일단 미리 말씀드리자면 결과 진짜 심각하게 시망했음…ㅋㅋㅋㅋㅋㅋ 걍 이렇게 하는구나만 알아두세요…
# 군집분석용
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import fcluster
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler # PCA에서 많이 보인 그 분
from sklearn.metrics import pairwise_distances # 저친구가 거리행렬을 안주면 유혈사태(아니고 에러사태)가 납니다
# k-means
from sklearn.cluster import KMeans
# k-medoid (이거 따로 까서야돼요)
import kmedoids
# 누구세요?
from sklearn.manifold import TSNE
# 통계분석용
from scipy import stats일단 넘파이 판다스 맷플롭 씨본에 쟤들 추가로 부르시고.
Hierarchical clustering
여기 어딘가에 있는 바이오파이썬 하다가 나온 그거 맞습니다. 이건 하게되면 결과물(?)이 덴드로그램으로 나와요.
data = shopping_df[['Age']] # 나이
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data) # 를 스케일링합니다category = np.array(shopping_df['Payment Method']) # 구매 방법
category = category.reshape(-1, 1)
encoder = OneHotEncoder().fit(category) ## 범주와 One-Hot Encoding간 매핑 생성
sparse_mat = encoder.transform(category) ## 실제로 변환할 때에는 transform 사용
sparse_mat = sparse_mat.toarray()combined_data = np.hstack([data_scaled, sparse_mat]) # 파이널- 퓨-전!!!나이는 수치형이라 스케일러 돌렸고, 구매 수단은 범주형이라 원 핫 인코딩 돌렸다. 그리고 합치면 준비 끝.
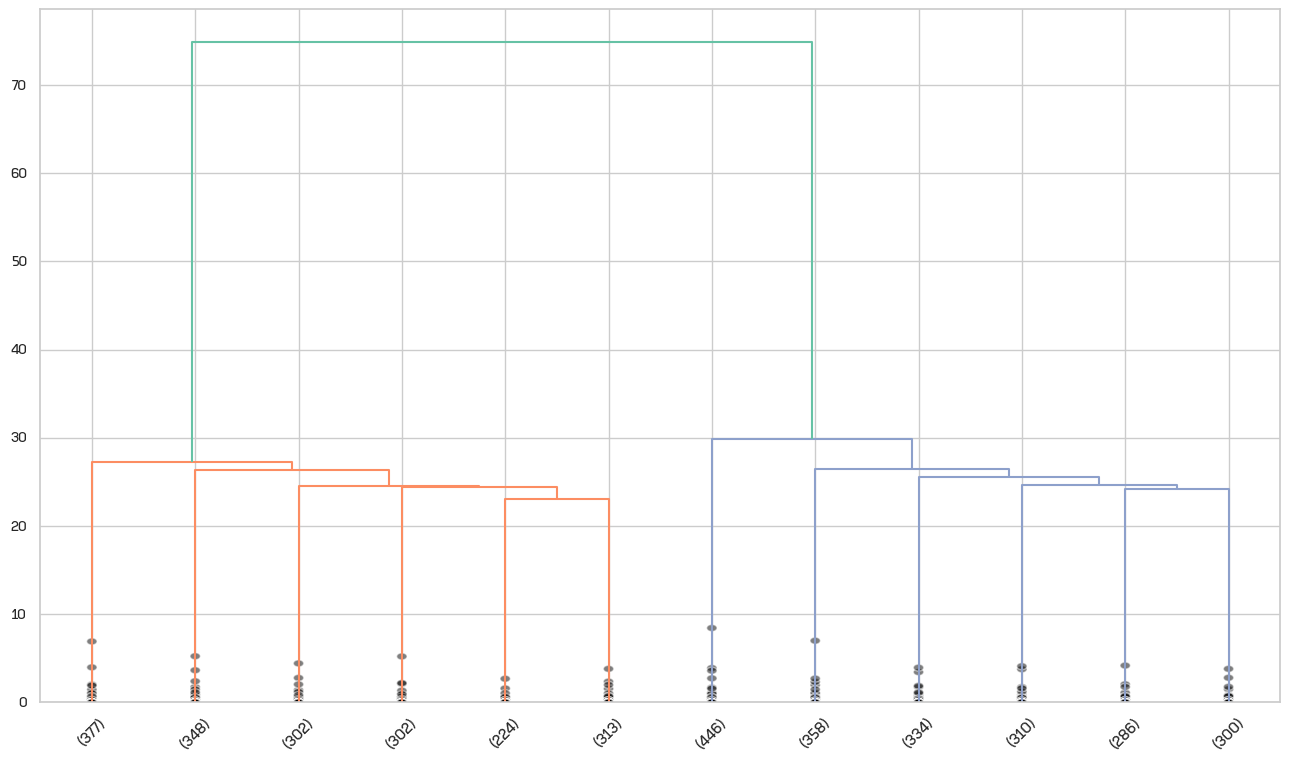
아 저 그리드 진짜 꼴뵈기싫어... ㅡㅡ 아무튼 이게 덴드로그램이다. 목을 오른쪽으로 90도 꺾고 보시면 그게 계통수입니다.
k-means&k-medoid
# 1. Inertia(오차 제곱합) 값을 저장할 리스트
inertia = []
k_range = range(1, 11) # 1개부터 10개까지 군집 개수를 늘려가며 확인
# 2. 반복문으로 각 K에 대한 모델 학습
for k in k_range:
# n_init=10: 초기 중심점을 10번 다르게 잡아서 최적의 결과를 선택
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(combined_data) # 나이(Scaled) + 결제수단(One-Hot) 데이터
inertia.append(kmeans.inertia_)
# 3. 그래프 시각화 (설정하신 NanumSquare가 적용됩니다)
plt.figure(figsize=(10, 6))
plt.plot(k_range, inertia, marker='o', color='forestgreen', linewidth=2)
plt.title('Optimal K 찾기 (Elbow Method)', fontsize=15)
plt.xlabel('군집 개수 (K)', fontsize=12)
plt.ylabel('Inertia (오차 제곱합)', fontsize=12)
plt.xticks(k_range)
plt.grid(True, alpha=0.3)
plt.show()저 k가 코리안의 k가 아니고 군집 개수다. 근데 그 군집 개수를 고스톱 쳐서 정하는 게 아니고 정하는 방법이 여러개가 있습니다. 여기서는 그 뭐라해야되지? 주성분분석때도 주성분 고른다고 했었던 그 엘보 찾는걸로 할겁니다.
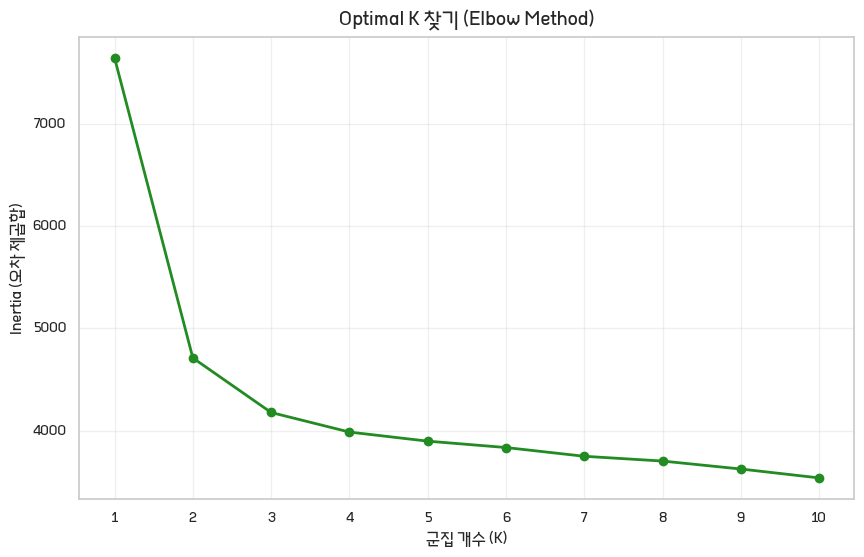
저 꺾은선을 보십시오. 2가 엘보다. 왜죠? 2에서 그래프의 기울기가 급격하게 변하거든요. 이렇게 되면 아 군집은 두개가 적당하구나... 하시면 된다.
# K-Means
kmeans4 = KMeans(n_clusters=4, random_state=42, n_init=10)
shopping_df['KMeans_K4'] = kmeans4.fit_predict(combined_data)
# 거리 행렬 & K-Medoids
dist_matrix = pairwise_distances(combined_data, metric='euclidean')
km_model = kmedoids.KMedoids(n_clusters=4, method='fasterpam', random_state=42)
km_result = km_model.fit(dist_matrix)
shopping_df['KMedoids_K4'] = km_result.labels_
# 대표 고객
medoid_indices = km_result.medoid_indices_
representative_customers = shopping_df.iloc[medoid_indices]
print(representative_customers[['Age', 'Purchase Amount (USD)']])한 블럭에 둘을 같이 돌렸는데.. 근데 둘이 뭔 차이임? k가 군집의 개수인 건 같은데, k-means는 평균이 기준이고 k-medoid는 중앙값이 기준입니다. 이렇게까지 나눠야 하나 싶으실텐데, 평균이 이상치의 영향을 되게 많이 받아요.
여러분 서울대에서 졸업생들 평균 연봉이 제일 높은 학과가 어딘지 아십니까? 공대? 아님. 의대? 아님. 서울대 사학과임. 아니 문사철의 그 사요? 재드래곤이랑 용진이횽이 거기 나와서 그렇게 된거임. 저 둘의 연봉이 어떻게 보면 이상치가 돼서 평균 연봉에 영향을 끼치는거예요.
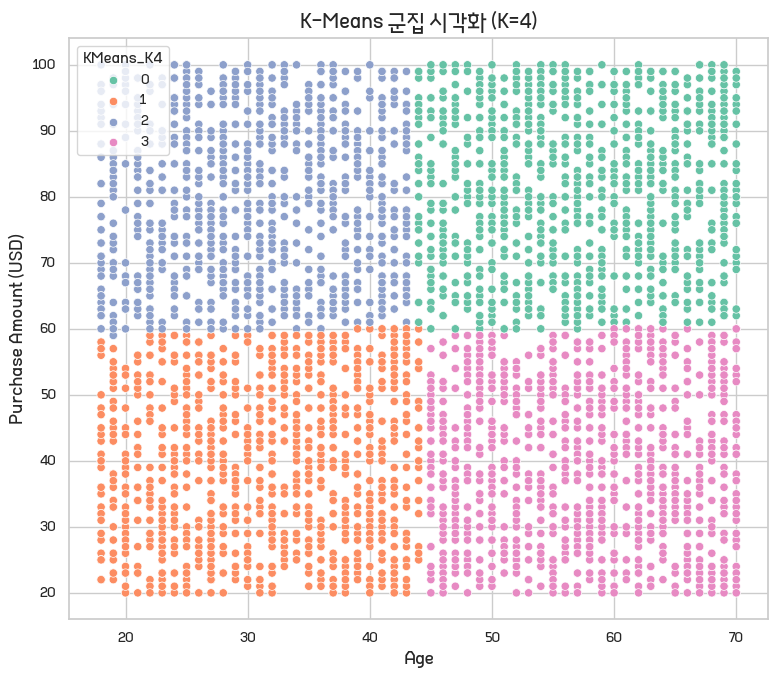

그럼 이게 왜 시망한건지 알려드리겠음. 이게 원래는 이렇게 안 나오고 점들이 일정 구역에 뭉쳐있습니다. 스타팅 포켓몬(최종진화체)으로 군집을 만든다 치면 불타입은 불타입끼리, 물타입은 물타입끼리, 풀타입은 풀타입끼리, 그리고 노랑뚱띠랑 이브이 따로 있을거란 말이죠. 그 안에서도 최종진화체가 단일타입인지 이중타입인지 혹은 종족값 이런걸로 세분화는 되겠지만 기본적으로 이 점들이 뭉쳐있어야 합니다.

이거는 MSA 얘기하면서 다시 얘기하겠지만 일단 이렇게 나와야 해요.
'Statics' 카테고리의 다른 글
| 귀무가설과 대립가설 (0) | 2026.02.12 |
|---|---|
| 통계는 실전이야: 상관분석 (0) | 2026.02.04 |
| 통계는 실전이야: ANOVA(feat. Tukey HSD) (0) | 2026.02.03 |
| 통계는 실전이야: Chi-square(카이제곱검정) (0) | 2026.02.02 |
| 정규성, 그리고 비모수검정 (0) | 2026.02.01 |