오늘 할 것은 피어슨 그리고 스피어만입니다. 둘이 뭔 차이인지는 이따 서술해드림.
들어가기 전에: 인과관계 vs 상관관계
인과관계랑 상관관계를 혼동하시는 분들이 많은데 둘이 엄연히 다른거다. 인과관계는 너때문에 흥이 다 깨졌으니까 책임져고 상관관계는 너의 등장과 흥이 깨진 것 사이에 뭔가 있는 것 같은데? 이다. 둘이 혼동하지 마십쇼. 상관관계는 너때문에 흥이 다 깨졌으니까 책임져가 아니고 너의 등장과 흥이 깨진 것 사이에 뭔가 있는 것 같은데? 를 보는거다. 너때문에 흥이 다 깨졌으니까 책임져는 회귀분석에서 보십쇼.
피어슨 상관계수
# 1. 선형 관계 데이터 (공부 시간 vs 시험 점수)
study_hours = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
test_scores = study_hours * 10 + np.random.normal(0, 5, 10) # 직선에 가깝게
# 피어슨 검정
corr_p, p_val_p = stats.pearsonr(study_hours, test_scores)
print(f"Pearson r: {corr_p:.4f}, p-value: {p_val_p:.4e}")Pearson r: 0.9950, p-value: 2.6606e-09음... 여기서 예시를 공부 시간과 성적으로 들긴 했는데... 여러분 이거 보고 거봐 어쨌든 오래 하면 된다니까? 하시면 안됩니다. 책상에 오래 붙어있는거랑 공부 시간이 긴 건 별개의 문제예요. 책상에 앉아서 딴짓 할 수도 있잖음. 그렇다고 또 옆에서 감시하면서 애 불편하게 만들진 마시고...
저 상관계수가 -1에서 1까지 범위인데, 1에 가까우면 양의 상관관계고 -1에 가까우면 음의 상관관계입니다. 0이면 노상관이다… 이렇게 보시면 됩니다.
엥? 근데 양의 상관관계는 뭐고 음의 상관관계는 뭐예요? 양의 상관관계는 정비례고 음의 상관관계는 반비례입니다. 자, 보세요. 포켓몬의 랭업기는 쓰는 횟수에 따라 스탯 랭업이 쌓이죠? 그리고 스탯 랭업이 쌓일때마다 공격이든 방어든 올라가죠? 양의 상관관계도 랭업기마냥 한쪽이 올라가면 다른쪽도 올라갑니다. 근데 그게 상관계수가 1(혹은 -1)에 가까운지에 따라 강하고 약하고가 정해지는거예요. 그 기준이 분야바이 분야입니다만
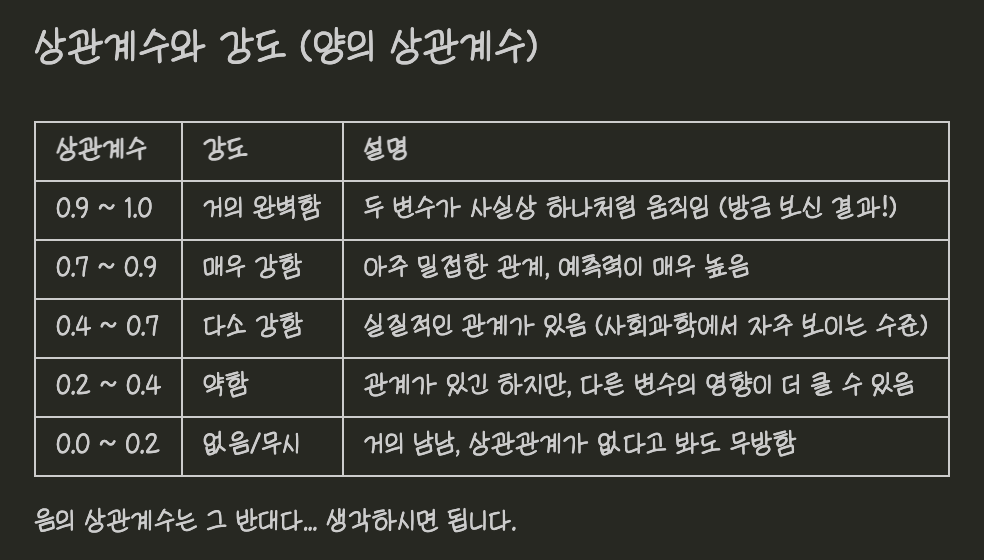
그냥 그런갑다... 하시면 됩니다. 음의 상관관계면 고 반대로 생각하시면 되고요.
data = pd.DataFrame({
'Study': study_hours,
'Score': test_scores
})
# 상관행렬 계산
corr_matrix = data.corr()
# 히트맵 그리기
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".4f")
plt.title('변수 간 상관관계 히트맵')
plt.show()
히트맵 원래 이렇게 이쁘게 안 나옵니다.
스피어만 상관계수
제 데이터가 수치형이 아닌데요! 아니 숫자긴 한데 별점이라 사실상 범주형인데요! 명목형인데요! 그러시면 피어슨 말고 스피어만 상관계수 쓰셔야 합니다. 저기 그 창병아저씨 ㄱㄱ하십쇼.
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = np.exp(x) # 직선이 아니라 확 꺾이는 곡선
# 스피어만 검정
corr_s, p_val_s = stats.spearmanr(x, y)
print(f"Spearman rho: {corr_s:.4f}, p-value: {p_val_s:.4e}")Spearman rho: 1.0000, p-value: 6.6469e-64이게… 이렇게 이쁘게 나올 리가 없는데…?
# 순위 변환
x_rank = pd.Series(x).rank()
y_rank = pd.Series(y).rank()
plt.figure(figsize=(10, 5))
# 1. 원본 데이터 산점도 (피어슨은 낮게, 스피어만은 높게 나옴)
plt.subplot(1, 2, 1)
plt.scatter(x, y, color='blue')
plt.title('Original Data (Non-linear)')
# 2. 순위 데이터 산점도 (스피어만의 시각화)
plt.subplot(1, 2, 2)
plt.scatter(x_rank, y_rank, color='red')
plt.title('Rank Data (Linear in Spearman)')
plt.tight_layout()
plt.show()
뭐 이렇게 시각화 하시든지.. 근데 얘를 시각화 힐 일이 있을지는 모르겠음.

인플루엔자 MSA 할 때 했던건데, 인플루엔자는 특정 아형 내에서 해마글루티닌 분석한거라 스피어만 상관계수로 들어갔었다.
'Statics' 카테고리의 다른 글
| 통계는 실전이야: 군집분석 (0) | 2026.02.19 |
|---|---|
| 귀무가설과 대립가설 (0) | 2026.02.12 |
| 통계는 실전이야: ANOVA(feat. Tukey HSD) (0) | 2026.02.03 |
| 통계는 실전이야: Chi-square(카이제곱검정) (0) | 2026.02.02 |
| 정규성, 그리고 비모수검정 (0) | 2026.02.01 |