https://www.kaggle.com/datasets/residentmario/ramen-ratings
Ramen Ratings
Over 2500 ramen ratings
www.kaggle.com
그... 돈코츠 이런거 아니고 우리 먹는 라면임다.
데이터 입수
import kagglehub
# Download latest version
path = kagglehub.dataset_download("residentmario/ramen-ratings")
print("Path to dataset files:", path)ramen_df = pd.read_csv(f'{path}/ramen-ratings.csv')우리는 지혜롭게 해결해야 합니다. 창고 원격으로 털어가라고 줬으면 걍 원격으로 털어갑시다.
전처리
결측값 처리
ramen_df['Style'] = ramen_df['Style'].fillna('Pack')
# 둘다 팩이래요찾아보니까 둘다 봉지라면이라서 그거 채웠음. Top 10에 결측값인거요? 그거는 걍 두셈.
문자인 척 하는 놈 검거
ramen_df['Stars'] = pd.to_numeric(ramen_df['Stars'], errors='coerce') # 별점
ramen_df['Review #'] = pd.to_numeric(ramen_df['Review #'], errors='coerce') # 리뷰 수니네 숫자인데 왜 오브젝트냐고…
브랜드명 통일
ramen_df['Brand'] = ramen_df['Brand'].replace('Chorip Dong', 'ChoripDong')
ramen_df['Brand'] = ramen_df['Brand'].replace('Samyang Foods', 'Samyang')얘들아… 브랜드좀 알아서 맞춰…
롸? 초립동? 저거 뭔 브랜드예요? 국내에서는 볼일이 잘 없는데, 본인이 재외동포거나 외국 여행갔다가 한인마트를 간 적 있다면 거기서 보셨을 것이다. 외국 한인마트에 들어가는 브랜드임.
줄바꿈이 왜 거기서 나와~
ramen_df['Top Ten'] = ramen_df['Top Ten'].replace('\n', np.nan, regex=True)뭘 쓰려다가 만겁니까 용사여...
국가별 분석
국가별 라면 개수
ramen_df_count = ramen_df.groupby('Country')['Review #'].agg('count').sort_values(ascending = False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(ramen_df_count, x = 'Country', y = 'Review #', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('국가별 라면 개수', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('라면 개수')
plt.xticks(rotation=90)
plt.show()
우리나라는 일본, 미국 다음으로 3위다.
별점 3점 이상인 라면
ramen_df_rating3 = ramen_df.query('Stars >= 3') # 별점 3점 이상
ramen_df_rating3 = ramen_df_rating3.groupby('Country')['Review #'].agg('count').sort_values(ascending = False).reset_index()
ramen_df_rating3['Review #']plt.figure(figsize = (18, 9))
ax = sns.barplot(ramen_df_rating3, x = 'Country', y = 'Review #', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('국가별 라면 개수 (별점 3점 이상)', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('라면 개수')
plt.xticks(rotation=90)
plt.show()
3점 이상인 라면은 미국보다 우리가 더 많음.
국가별 별점 평균
ramen_df_mean = ramen_df.groupby('Country')['Stars'].agg('mean').sort_values(ascending = False).reset_index()
ramen_df_meanplt.figure(figsize = (18, 9))
ax = sns.barplot(ramen_df_mean, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.xlabel('국가')
plt.ylabel('별점 평균')
plt.xticks(rotation=90)
plt.title('국가별 라면 별점 평균', fontsize = 20)
plt.show()
음... 브라질은 의외구만.
국가별로 별점이 제일 높은 라면
high_star_idx = ramen_df.dropna(subset=['Country', 'Stars']).groupby('Country')['Stars'].idxmax()
ramen_df.loc[high_star_idx].sort_values('Stars', ascending = False).reset_index() index Review # Brand Variety Style Country Stars Top Ten
0 512 2068 Maggi Fusian Special Edition Ow... Ow... Spicy Cow M... Pack Australia 5.00 NaN
1 251 2329 Patanjali Atta Noodles Jhatpat Banao Befikr Khao Pack India 5.00 NaN
2 11 2569 Yamachan Yokohama Tonkotsu Shoyu Pack USA 5.00 NaN
3 380 2200 Mr. Lee's Noodles Shaolin Monk Vegetables Cup UK 5.00 NaN
4 10 2570 Tao Kae Noi Creamy tom Yum Kung Flavour Pack Thailand 5.00 NaN
5 65 2515 Uni-President Man Han Feast Spicy Beef Flavor Instant Noodles Bowl Taiwan 5.00 NaN
6 30 2550 Samyang Paegaejang Ramen Pack South Korea 5.00 NaN
7 22 2558 KOKA Creamy Soup With Crushed Noodles Hot & Sour Fi... Cup Singapore 5.00 NaN
8 883 1697 The Kitchen Food Instant Kampua Dark Soy Sauce Pack Sarawak 5.00 NaN
9 2033 547 Lucky Me! Pancit Canton Sweet Spicy Pack Philippines 5.00 NaN?? 삼양에서 파개장 라면을 냈었음? 저 왜 못봤죠?
K-라면
k_ramen = ramen_df.query('Country == "South Korea"') # 니네 DB에 이북산 라면도 있니?
k_ramen저거 어차피 한국 라면밖에 없음... 노스 없으니까 번잡시러우시면 Korea로 바꾸십셔.
브랜드별 라면 개수
k_ramen_cnt = k_ramen.groupby('Brand')['Stars'].agg('count').sort_values(ascending = False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(k_ramen_cnt, x = 'Brand', y = 'Stars', hue = 'Brand', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('브랜드별 K-라면 개수', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('라면 개수')
plt.xticks(rotation=90)
plt.show()
삼양, 팔도, 농심, 오뚜기가 압도적이고 그 다음이 풀무원이다. 저 다섯개 브랜드 라면 함 까봐야징.
브랜드별 평균 별점
k_ramen_mean = k_ramen.groupby('Brand')['Stars'].agg('mean').sort_values(ascending = False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(k_ramen_mean, x = 'Brand', y = 'Stars', hue = 'Brand', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('국가별 라면 별점', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('라면 개수')
plt.xticks(rotation=90)
plt.show()
그… 많이 판다고 별점까지 다 좋진 않아요…
개별 브랜드-팔도
paldo = k_ramen.query('Brand == "Paldo"')
paldo # 불닭 언제 나오나 본다 내가불닭볶음면은 삼양이니까 한참 더 가셔야됩니다.
팔도의 5성급 라면
paldo_5_star = paldo.query('Stars >= 5')
paldo_5_star Review # Brand Variety Style Country Stars Top Ten
97 2483 Paldo Bul Jjamppong Bowl South Korea 5.0 NaN
256 2324 Paldo Bul Jjajangmyeon Pack South Korea 5.0 NaN
346 2234 Paldo Bibim Men Bowl South Korea 5.0 NaN
360 2220 Paldo Budae Jjigae Pack South Korea 5.0 NaN
826 1754 Paldo King Bowl Super Spicy Pan Stirfried Noodle Bowl South Korea 5.0 NaN
903 1677 Paldo Raobokki Noodle (Export Version) Pack South Korea 5.0 NaN
1005 1575 Paldo Jjajangmen Chajang Noodle King Bowl Bowl South Korea 5.0 NaN
1057 1523 Paldo Jjamppong Seafood Noodle King Bowl Bowl South Korea 5.0 NaN
1166 1414 Paldo Cheese Ramyun (for US market) Pack South Korea 5.0 NaN
1266 1314 Paldo Korean Traditional Beef Gomtangmen Pack South Korea 5.0 NaN
1397 1183 Paldo Cheese Noodle Pack South Korea 5.0 2014 #6
1648 932 Paldo Namja Ramen (USA version) Pack South Korea 5.0 NaN
1754 826 Paldo Namja Pack South Korea 5.0 NaN
1756 824 Paldo Bibim Men Cucumber Pack South Korea 5.0 NaN
1757 823 Paldo Kokomen Spicy Chicken Pack South Korea 5.0 2013 #9
1906 674 Paldo Kko Kko Myun Pack South Korea 5.0 NaN어... 나도 꼬꼬면 참 좋아해... 좋아하는데... 이정도로 월클일 줄 몰랐어... 비빔면은 나는 매워서 못먹지만 솔직히 월클일만 했음.
도시락
target_ramens = paldo[paldo['Variety'].str.contains('Dosirac', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
1579 Paldo ДОШИРАК (Dosirac) Beef Flavor 3.500
2266 Paldo Dosirac Mushroom 2.500
2267 Paldo Dosirac Shrimp 4.250
2271 Paldo Dosirac Beef 3.750
2277 Paldo Dosirac Artificial Chicken 3.250
2404 Paldo Dosirac Pork 4.125리뷰어 양반… 편의점에 김치도시락 있으니까 먹어보라우… 저게 그 어머니 러시아에서 히트라는 네모네모 라면입니다. 아 왕뚜껑이요? 나도 좋아해 좋아하는데 영어로 뭐라고 하는지 몰라…
개별 브랜드-농심
nongshim = k_ramen.query('Brand == "Nongshim"')
nongshim # 불닭 언제 나오나 본다 내가내가 신라면은 매워서 못먹고… 새우탕면 맛있습니다. 백목이버섯 불려서 슬금슬금 넣어먹으면 아주 국물이 크… 그 백목이버섯은 국물이 약간 매콤한 라면이랑 어울려요. 진라면 약간매운맛이나 새우탕면같은… 나중에 오징어짬뽕으로도 테스트해보겠음.
농심 5성급
nongshim_5_star = nongshim.query('Stars >= 5')
nongshim_5_starReview # Brand Variety Style Country Stars Top Ten
47 2533 Nongshim Shin Ramyun Black Pack South Korea 5.0 NaN
419 2161 Nongshim Chal Bibim Myun Pack South Korea 5.0 NaN
486 2094 Nongshim Champong Noodle Soup Spicy Seafood Flavor Pack South Korea 5.0 NaN
753 1827 Nongshim Zha Wang ((Jjawang) Noodles With Chajang Sauce Pack South Korea 5.0 NaN
979 1601 Nongshim Jinjja Jinjja (New) Pack South Korea 5.0 NaN
1272 1308 Nongshim Soon Veggie Noodle Soup Pack South Korea 5.0 2014 #9
1475 1105 Nongshim Doong Ji Authentic Korean Cold Noodles With Ch... Tray South Korea 5.0 NaN
1829 751 Nongshim Shin Ramyun Black Onion Cup South Korea 5.0 NaN
1835 745 Nongshim Jinjja Jinjja Pack South Korea 5.0 NaN그... 둥지냉며어어어어어언이요... 조낸 비싸요... 조낸 비싼데 조낸 간단해... 우리가 모밀이나 비빔면은 라면류가 많지만 냉면은 쟤 하나거든요? 아 그래서 비싸게 받는건가... 아무튼 이게 냉면인데 걍 라면 끓여먹듯 끓이면 되고 국물도 물타면 땡입니다. 조낸 비싼거 빼면 다 좋음. 집에 김치 있어요? 백김치건 동치미건 말아잡수면 최고임.
너구리
target_ramens = nongshim[nongshim['Variety'].str.contains('Neoguri', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
1065 Nongshim Neoguri Udon Seafood & Mild 4.00
1673 Nongshim Neoguri Spicy Seafood 4.00
1771 Nongshim Neoguri Mild (South Korea) 4.00
2079 Nongshim Neoguri Mild 3.25
2560 Nongshim Neoguri (Seafood'n'Spicy) 3.50너구리가… 한국판이랑 걍 너구리랑 뭔 차이임? 수출버전에는 다시마가 없어?
신라면
target_ramens = nongshim[nongshim['Variety'].str.contains('Shin', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
47 Nongshim Shin Ramyun Black 5.00
76 Nongshim Shin Ramyun 3.00
1393 Nongshim Shin Ramyun Cup 3.50
1582 Nongshim Shin Ramyun Black Spicy Beef 4.50
1829 Nongshim Shin Ramyun Black Onion 5.00
2002 Nongshim Shin Ramyun Black 4.75
2238 Nongshim Shin Big Bowl 3.50
2289 Nongshim Shin Bowl 3.00
2561 Nongshim Shin Ramyun 4.00신라면 블랙이랑 블랙어년이 5점이다. 나는 저 라인은 다 매워서 못먹음...
안성탕면
target_ramens = nongshim[nongshim['Variety'].str.contains('Ansungtangmyun', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
2558 Nongshim Ansungtangmyun Noodle Soup 3.75자네 빨리 와서 순하리랑 해물 안성탕면좀 먹고 가게.
개별 브랜드-삼양
samyang = k_ramen.query('Brand == "Samyang"')
samyang # 불닭 거기불닭볶음면으로 킹이 된 삼양… 정확히는 삼양식품이요.
5성급 라면
samyang_5_star = samyang.query('Stars >= 5')
samyang_5_star Review # Brand Variety Style Country Stars Top Ten
30 2550 Samyang Paegaejang Ramen Pack South Korea 5.0 NaN
69 2511 Samyang Samyang Ramen Classic Edition Bowl South Korea 5.0 NaN
214 2366 Samyang Buldak Bokkeummyun Snack Pack South Korea 5.0 NaN
215 2365 Samyang Stew Buldak Bokkeumtangmyun Pack South Korea 5.0 NaN
298 2282 Samyang Gold Jjamppong Fried Noodle Pack South Korea 5.0 NaN
606 1974 Samyang Cheese Curry Ramyun Pack South Korea 5.0 NaN
1280 1300 Samyang Red Nagasaki Jjampong Pack South Korea 5.0 NaN
1382 1198 Samyang Maesaengyitangmyun Baked Noodle Pack South Korea 5.0 2014 #5
1551 1029 Samyang Nagasaki Crab Jjampong Pack South Korea 5.0 NaN아 불닭볶음면이 국물버전이 있어?
불닭볶음면 씨리즈
target_ramens = samyang[samyang['Variety'].str.contains('Buldak', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
72 Samyang Mala Buldak Bokkeummyun 3.75
99 Samyang Buldak Bokkeummyun 3.75
156 Samyang Cheese Type Buldak Bokkeummyun (Black Pkg) 3.75
183 Samyang Cheese Buldak Bokkeummyun (Black) 4.00
210 Samyang Zzaldduck Buldak Bokkeummyun Snack 4.50
211 Samyang Curry Buldak Bokkeummyun 4.25
212 Samyang Cool/Ice Buldak Bokkeummyun 3.75
213 Samyang 2x Spicy Haek Buldak Bokkeummyun 4.00
214 Samyang Buldak Bokkeummyun Snack 5.00
215 Samyang Stew Buldak Bokkeumtangmyun 5.00
216 Samyang Cheese Buldak Bokkeummyun 4.00
217 Samyang Buldak Bokkeummyun (New Packaging) 4.00
289 Samyang Buldak Bokkummyun Cheese Flavor 4.00
1150 Samyang Buldak Bokkummyeon 4.00불닭볶음면이 왜 두개니…
핵불닭은 별 4개다. ...당신들 다음날 내장은 괜찮은겁니까?
삼양라면
target_ramens = samyang[samyang['Variety'].str.contains('Samyang Ramen|Samyang Ramyun', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
69 Samyang Samyang Ramen Classic Edition 5.00
1330 Samyang 三養라면 (Samyang Ramyun) (South Korean Version) 3.75
1467 Samyang Samyang Ramyun (SK Version) 3.50
1557 Samyang Samyang Ramyun 4.50저 클래식은 대체 뭘까… 예전에 그 투명포장에 삼양라-면 있고 닭어쩌고 하던 그건가?
개별 브랜드-오뚜기
ottogi = k_ramen.query('Brand == "Ottogi"')
ottogi
오뚜기의 5성급 라면
ottogi_5_star = ottogi.query('Stars >= 5')
ottogi_5_star Review # Brand Variety Style Country Stars Top Ten
189 2391 Ottogi Jin Jjambbong Spicy Seafood Ramyun Pack South Korea 5.0 NaN저거 굴진짬뽕도 맛있습니다. 개인적으로 흰 국물이라 나는 굴진짬뽕을 더 좋아함.
진라면
target_ramens = ottogi[ottogi['Variety'].str.contains('Jin Ramen', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
1800 Ottogi Jin Ramen (Mild) (Import) 3.50
1959 Ottogi Jin Ramen Big Bowl (Hot) 3.50
2085 Ottogi Jin Ramen (Mild) 3.25
2185 Ottogi Jin Ramen (Mild) 3.00
2257 Ottogi Jin Ramen (Hot) 3.50
2562 Ottogi Jin Ramen (Hot Taste) 3.50그... 외국에는 약간매운맛이 없음?
진순 vs 진매
jin_mild = ottogi[ottogi['Variety'].str.contains('Mild', case=False)]
jin_hot = ottogi[ottogi['Variety'].str.contains('Hot', case=False)]
mean_mild = np.mean(jin_mild['Stars'])
mean_hot = np.mean(jin_hot['Stars'])
print(f'진순이 별점: {mean_mild} | 진매 별점 {mean_hot}')
if mean_mild > mean_hot:
print('진순이 만세!')
else:
print('진순이 매니아는 웁니다. ')진순이 별점: 3.25 | 진매 별점 3.4
진순이 매니아는 웁니다.아니! 진순이가! 어때서!
참깨라면
target_ramens = ottogi[ottogi['Variety'].str.contains('Sesame', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
930 Ottogi Sesame Flavor Ramen Korean Style Instant Noodle 4.25
1572 Ottogi Sesame Flavor Noodle Bowl 3.50어… 그렇구나…
오동통
target_ramens = ottogi[ottogi['Variety'].str.contains('Odongtong', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
1845 Ottogi Odongtong Myon Seafood 2.75
2469 Ottogi Odongtongmyon Seafood Spicy 3.25자네... 다시마 두개 들어간거 먹어본거지...?
뿌셔뿌셔는 스낵이여 이사람들아
target_ramens = ottogi[ottogi['Variety'].str.contains('Ppushu', case=False)]
print(target_ramens[['Brand', 'Variety', 'Stars']]) Brand Variety Stars
50 Ottogi Ppushu Ppushu Noodle Snack Honey Butter 2.00
106 Ottogi Ppushu Ppushu Noodle Snack Chilli Cheese Flavor 4.25
1162 Ottogi Ppushu Ppushu Grilled Chicken Flavor 1.00
1302 Ottogi Ppushu Ppushu Noodle Snack Bulgogi Flavor 3.25
2117 Ottogi Ppushu Ppushu Barbecue 3.00
2130 Ottogi Ppushu Ppushu Tteobokki 3.25
2341 Ottogi Ppushu Ppushu Sweet & Sour 1.75이건 라면이 아니고 부셔먹으라고 나온 과자인데 왜 여기 있는거임?
개별 브랜드-풀무원
pulmuone = k_ramen.query('Brand == "Pulmuone"')
pulmuone # 불닭 옛저녁에 나옴얘네가 라면이 있나 싶으실텐데 그 로스팅 시리즈 있습니다. 파기름 짜장 맛있음.
풀무원의 5성급
pulmuone_5_star = pulmuone.query('Stars >= 5')
pulmuone_5_star Review # Brand Variety Style Country Stars Top Ten
393 2187 Pulmuone Non-Fried Ramyun Noodle (Crab Flavor) Pack South Korea 5.0 NaN저거 로스팅 홍게짬뽕인가? 안먹어봤는데 기회가 된다면 백목이버섯 불려서 넣은거 먹어보고 싶음.
TOP 10 노미네이트
k_ramen.query('not `Top Ten`.isna()') Review # Brand Variety Style Country Stars Top Ten
1272 1308 Nongshim Soon Veggie Noodle Soup Pack South Korea 5.00 2014 #9
1382 1198 Samyang Maesaengyitangmyun Baked Noodle Pack South Korea 5.00 2014 #5
1397 1183 Paldo Cheese Noodle Pack South Korea 5.00 2014 #6
1757 823 Paldo Kokomen Spicy Chicken Pack South Korea 5.00 2013 #9
2002 578 Nongshim Shin Ramyun Black Pack South Korea 4.75 2012 #7오오 꼬꼬면 오오
TOP 10
가장 많이 입성한 국가
top10_nominated = ramen_df.query('not `Top Ten`.isna()')
top10_nominated_cnt = top10_nominated.groupby('Country')['Variety'].agg('count').sort_values(ascending = False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(top10_nominated_cnt, x = 'Country', y = 'Variety', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('국가별 Top 10에 입성한 개수', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('입성한 라면')
plt.xticks(rotation=90)
plt.show()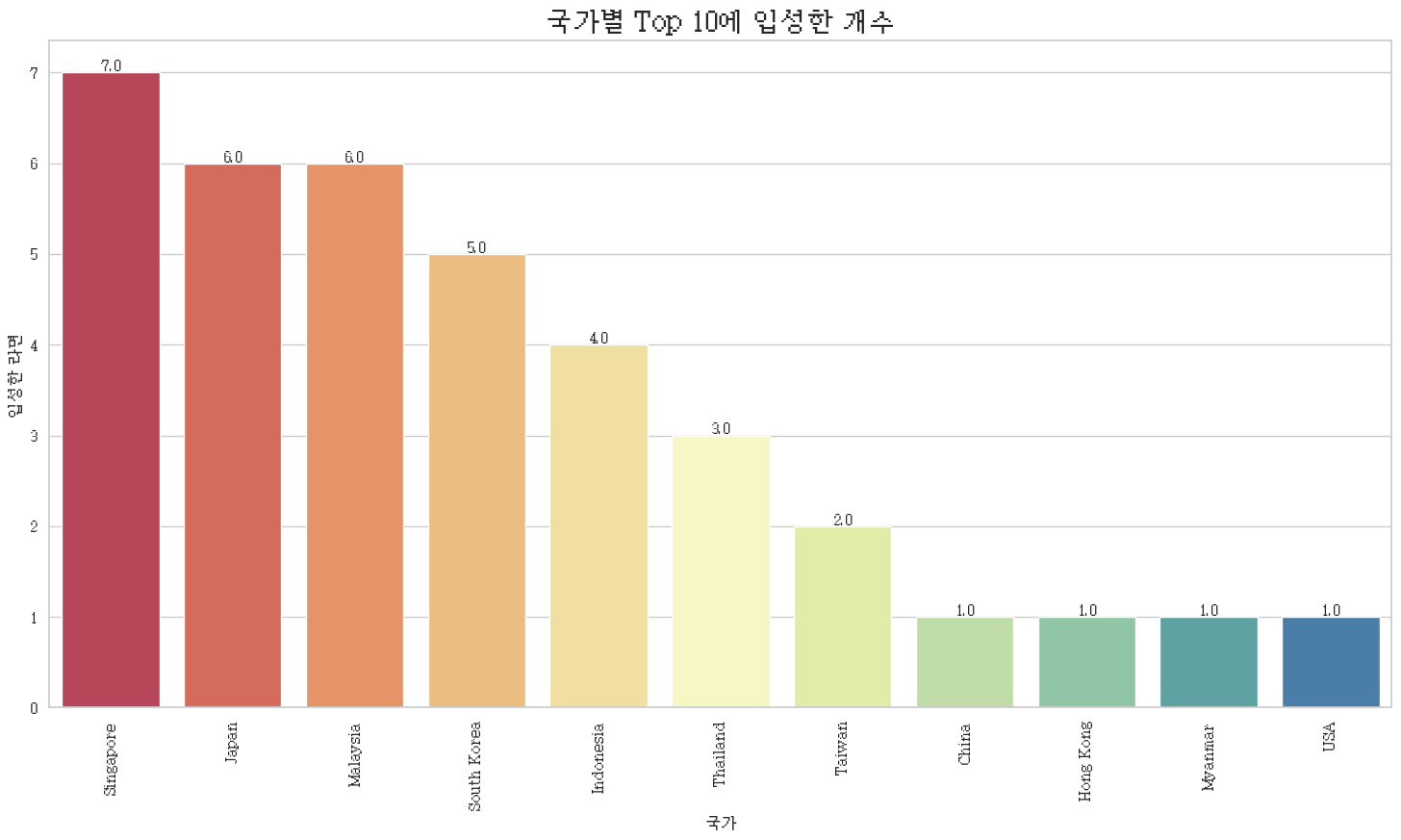
싱가포르 라면 궁금하구만. 말레이시아는 숨겨진 라면계의 강자라고 합니다.
TOP 10 별점 평균
top10_nominated_mean = top10_nominated.groupby('Country')['Stars'].agg('mean').sort_values(ascending = False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(top10_nominated_mean, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.2f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('국가별 Top 10에 입성한 라면들의 별점 평균', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('입성한 라면들의 별점 평균')
plt.xticks(rotation=90)
plt.show()
우리나라 라면은 아쉽게도 근소하게 빗나갔음…
별점 1점인 라면
ramen_df.query("Stars < 1")거 클로렐라면은 대체…
ramen_under_1 = ramen_df.query("Stars < 1").groupby('Country')['Stars'].agg('count').sort_values(ascending=False).reset_index()plt.figure(figsize = (18, 9))
ax = sns.barplot(ramen_under_1, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral')
# 라벨 박아줘야죠
for i in ax.patches:
height = i.get_height()
ax.annotate(f'{height:.1f}', # 표시할 텍스트 (소수점 1자리)
(i.get_x() + i.get_width() / 2., height), # 위치: 막대 중앙 상단
ha='center', va='bottom', size=11) # 정렬 및 크기
plt.title('별점 1점 미만인 라면들의 국가 분포', fontsize = 20)
plt.xlabel('국가')
plt.ylabel('1점 미만인 라면 개수')
plt.xticks(rotation=90)
plt.show()
중국이랑 미국이 공동 1위다.
컵라면 vs 봉지라면
style_cup = ['Cup', 'Bowl']
style_pack = ['Pack']
ramen_cup = ramen_df.query('Style in @style_cup')
ramen_pack = ramen_df.query('Style in @style_pack')컵이랑 볼은 왜 나누는겨…
5점대&1점 미만 비율
# 컵라면(Cup, Bowl) 비율 계산
cup_counts = ramen_cup['Stars'].value_counts(normalize=True)
cup_5 = cup_counts.get(5, 0) * 100
cup_under_1 = cup_counts[cup_counts.index < 1].sum() * 100
# 봉지라면(Pack) 비율 계산
pack_counts = ramen_pack['Stars'].value_counts(normalize=True)
pack_5 = pack_counts.get(5, 0) * 100
pack_under_1 = pack_counts[pack_counts.index < 1].sum() * 100
# 결과 출력
print(f"[컵라면] 5점 비율: {cup_5:.2f}%, 1점 미만 비율: {cup_under_1:.2f}%")
print(f"[봉지라면] 5점 비율: {pack_5:.2f}%, 1점 미만 비율: {pack_under_1:.2f}%")[컵라면] 5점 비율: 13.86%, 1점 미만 비율: 2.79%
[봉지라면] 5점 비율: 15.62%, 1점 미만 비율: 1.63%음... 쪽수도 쪽수인데... 전체적으로 컵라면이 호평받기가 빡신가배...
5점짜리 국가 분포
cup_5_cnt = cup_5star.groupby('Country')['Stars'].agg('count').sort_values(ascending=False).reset_index() # 컵
pack_5_cnt = pack_5star.groupby('Country')['Stars'].agg('count').sort_values(ascending=False).reset_index() # 팩fig, ax = plt.subplots(1,2, figsize=(20, 10))
ax[0] = sns.barplot(cup_5_cnt, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral', ax=ax[0], legend=False)
ax[0].set_title('컵라면 별점 5점짜리 국가 분포', fontsize = 20)
ax[0].set_xlabel('국가')
ax[0].set_ylabel('개수')
ax[0].tick_params(axis='x', rotation=90)
ax[1] = sns.barplot(pack_5_cnt, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral', ax=ax[1], legend=False)
ax[1].set_title('봉지라면 별점 5점짜리 국가 분포', fontsize = 20)
ax[1].set_xlabel('국가')
ax[1].set_ylabel('개수')
ax[1].tick_params(axis='x', rotation=90)
# 레이아웃 조정 후 출력
plt.tight_layout()
plt.show()
일본이 컵라면 본좌긴 하지...
1점 미만 국가 분포
cup_1_cnt = cup_1star.groupby('Country')['Stars'].agg('count').sort_values(ascending=False).reset_index() # 컵
pack_1_cnt = pack_1star.groupby('Country')['Stars'].agg('count').sort_values(ascending=False).reset_index() # 팩fig, ax = plt.subplots(1,2, figsize=(20, 10))
ax[0] = sns.barplot(cup_1_cnt, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral', ax=ax[0], legend=False)
ax[0].set_title('컵라면 별점 1점짜리 국가 분포', fontsize = 20)
ax[0].set_xlabel('국가')
ax[0].set_ylabel('개수')
ax[0].tick_params(axis='x', rotation=90)
ax[1] = sns.barplot(pack_1_cnt, x = 'Country', y = 'Stars', hue = 'Country', palette = 'Spectral', ax=ax[1], legend=False)
ax[1].set_title('봉지라면 별점 1점짜리 국가 분포', fontsize = 20)
ax[1].set_xlabel('국가')
ax[1].set_ylabel('개수')
ax[1].tick_params(axis='x', rotation=90)
# 레이아웃 조정 후 출력
plt.tight_layout()
plt.show()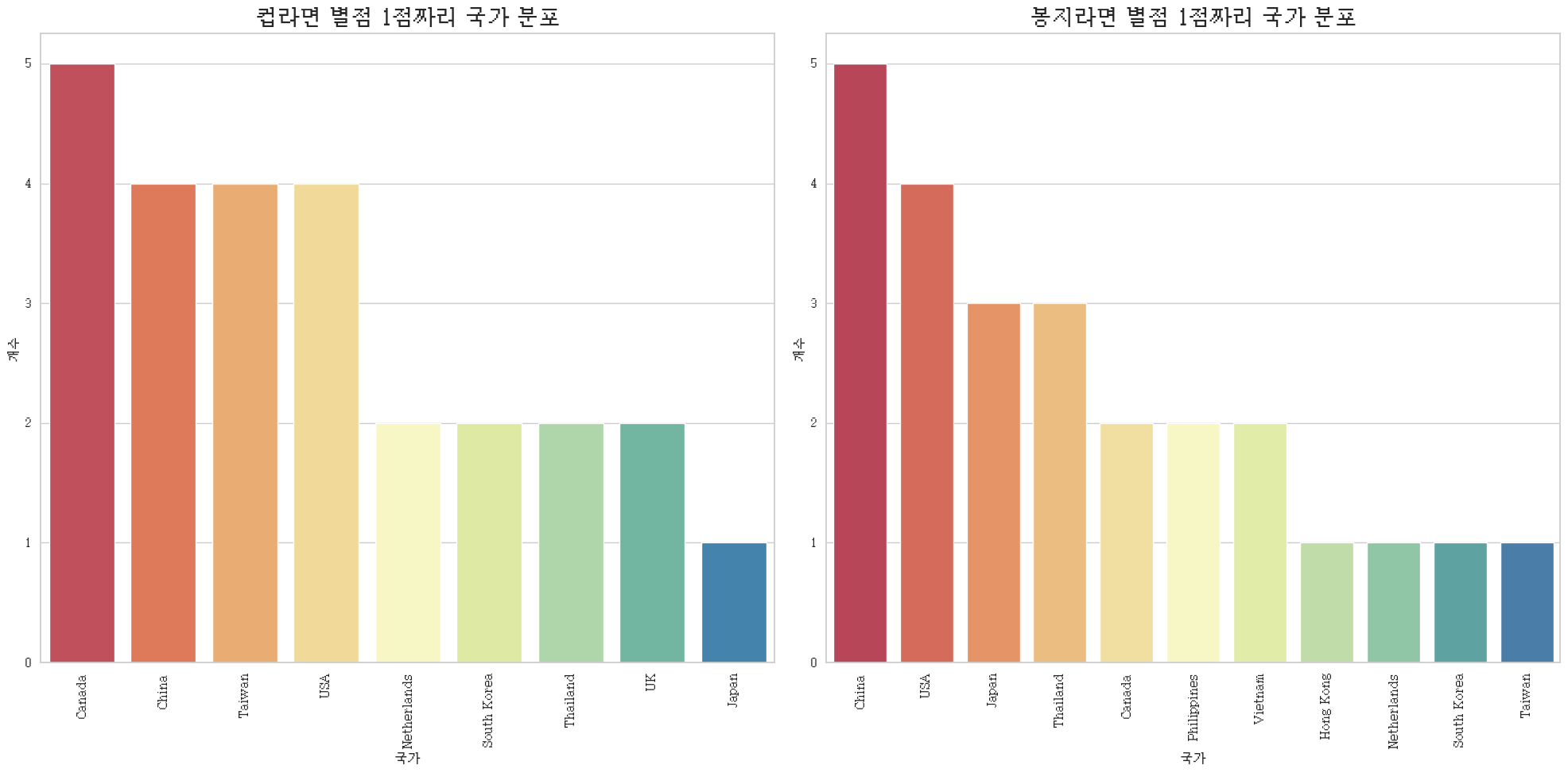
??? 컵라면은 왜 캐나다가 1위여? 라면에 메이플시럽 넣었냐 니네?
K-라면의 비중
# 국가가 사우쓰 코리아냐 아니냐로 구별
# 람다식 쓰시져
ramen_cup_kor = ramen_cup.copy()
ramen_cup_kor['Country'] = ramen_cup['Country'].apply(lambda x:"K-ramyeon" if x == "South Korea" else "Other")
ramen_pack_kor = ramen_pack.copy()
ramen_pack_kor['Country'] = ramen_pack['Country'].apply(lambda x:"K-ramyeon" if x == "South Korea" else "Other")# 1. 데이터 집계 (Cup & Pack 각각)
cup_counts = ramen_cup_kor['Country'].value_counts()
pack_counts = ramen_pack_kor['Country'].value_counts()
# 2. 파이차트 그리기 (1행 2열)
fig, ax = plt.subplots(1, 2, figsize=(14, 7))
# 공통 스타일 설정
colors = ['#ff9999', '#ffc000'] # K-ramyeon은 눈에 띄게!
explode = [0.1, 0] # K-ramyeon 살짝 튀어나오게
# 컵라면 파이차트
ax[0].pie(cup_counts, labels=cup_counts.index, autopct='%1.1f%%',
startangle=90, colors=colors, explode=explode, shadow=True)
ax[0].set_title('컵라면: 한국 vs 타국가 비율', fontsize=16)
# 봉지라면 파이차트
ax[1].pie(pack_counts, labels=pack_counts.index, autopct='%1.1f%%',
startangle=90, colors=colors, explode=explode, shadow=True)
ax[1].set_title('봉지라면: 한국 vs 타국가 비율', fontsize=16)
plt.tight_layout()
plt.show()
봉지라면의 비율이 쬐끔 더 높다.
TOP 10의 비중
cup_top10 = ramen_cup.copy()
pack_top10 = ramen_pack.copy()
cup_top10['Is Top Ten'] = cup_top10['Top Ten'].apply(lambda x: 'Top Ten' if pd.notnull(x) and x != '' else 'None')
pack_top10['Is Top Ten'] = pack_top10['Top Ten'].apply(lambda x: 'Top Ten' if pd.notnull(x) and x != '' else 'None')# 1. 데이터 집계 (Cup & Pack 각각)
cup_counts = cup_top10['Is Top Ten'].value_counts()
pack_counts = pack_top10['Is Top Ten'].value_counts()
# 2. 파이차트 그리기 (1행 2열)
fig, ax = plt.subplots(1, 2, figsize=(14, 7))
# 공통 스타일 설정
colors = ['#ff9999', '#ffc000'] # K-ramyeon은 눈에 띄게!
explode = [0.1, 0] # K-ramyeon 살짝 튀어나오게
# 컵라면 파이차트
ax[0].pie(cup_counts, labels=cup_counts.index, autopct='%1.1f%%',
startangle=90, colors=colors, shadow=True)
ax[0].set_title('컵라면: TOP 10 비율', fontsize=16)
# 봉지라면 파이차트
ax[1].pie(pack_counts, labels=pack_counts.index, autopct='%1.1f%%',
startangle=90, colors=colors, explode=explode, shadow=True)
ax[1].set_title('봉지라면: TOP 10 비율', fontsize=16)
plt.tight_layout()
plt.show()
컵라면은 없고요...
# 컵라면 중 Top Ten에 선정된 녀석들만 추출
pack_top10_winners = pack_top10.query('`Is Top Ten` == "Top Ten"')
# 그 안에서 국가별 비중 확인
pack_top10_korea = pack_top10_winners['Country'].value_counts()
print("Top 10에 선정된 봉지라면들의 국적 분포:")
print(pack_top10_korea)# 컵라면 중 Top Ten에 선정된 제품의 브랜드와 제품명 출력
elite_pack = pack_top10.query('`Is Top Ten` == "Top Ten" and Country == "South Korea"')[['Brand', 'Variety', 'Country', 'Top Ten']]
print("--- 봉지라면계의 전설(들) ---")
print(elite_pack)--- 봉지라면계의 전설(들) ---
Brand Variety Country Top Ten
1272 Nongshim Soon Veggie Noodle Soup South Korea 2014 #9
1382 Samyang Maesaengyitangmyun Baked Noodle South Korea 2014 #5
1397 Paldo Cheese Noodle South Korea 2014 #6
1757 Paldo Kokomen Spicy Chicken South Korea 2013 #9
2002 Nongshim Shin Ramyun Black South Korea 2012 #7내 꼬꼬면은 남격때부터 챙겨먹었다만... 이정도일 줄 몰랐고...
'Coding > EDA' 카테고리의 다른 글
| 얘! clinvar도 EDA가 된단다! (2) (0) | 2026.02.17 |
|---|---|
| 얘! clinvar도 EDA가 된단다! (1) (0) | 2026.02.15 |
| Post-COVID Video Games Worldwide (2021-2025) (0) | 2026.02.10 |
| 또 ChEMBL을 털어보았다 (0) | 2026.01.28 |
| 캐글 EDA-마! 서퍼티파이! (2) (0) | 2026.01.20 |