https://koreanraichu.tistory.com/839
캐글 EDA-마! 서퍼티파이!
https://www.kaggle.com/datasets/serkantysz/550k-spotify-songs-audio-lyrics-and-genres/data 550K Spotify Songs: Audio, Lyrics & GenresEnhanced Music Dataset with Audio Features, Lyrics, Genres & Artist Metadatawww.kaggle.com참고로 본인은 스포티파
koreanraichu.tistory.com
우리 어제 전처리까지 하고 끝냈음… 기억하시죠? 하다하다 VScode가 뻗었다고…
아티스트 분석
여기는 뭐 없어서 분량도 짧다.
# 1그룹에 다 몰렸구나...
# 결측값을 0으로 채움
genre_follower = artist_df.groupby(['main_genre','follower_group'], observed=True)['id'].size().unstack()
# 각 장르별 합계
genre_follower['total_group'] = genre_follower.sum(axis=1)
# 정렬
genre_sort = genre_follower.sort_values('total_group', ascending=False)
genre_sort그… 우리 어제 cut으로 나눈거 기억하시죠? 근데 판다스에는 걍 컷 말고 큐컷이 있다. 이건 또 뭔데요? 컷은 우리가 기준을 정하는거고, 큐컷은 알아서 n등분 하쇼~ 하면 판다스가 나눠준다.
sns.barplot(genre_sort, x = 'main_genre', y = 'total_group', hue = 'main_genre')
plt.xlabel('장르')
plt.ylabel('아티스트')
plt.show()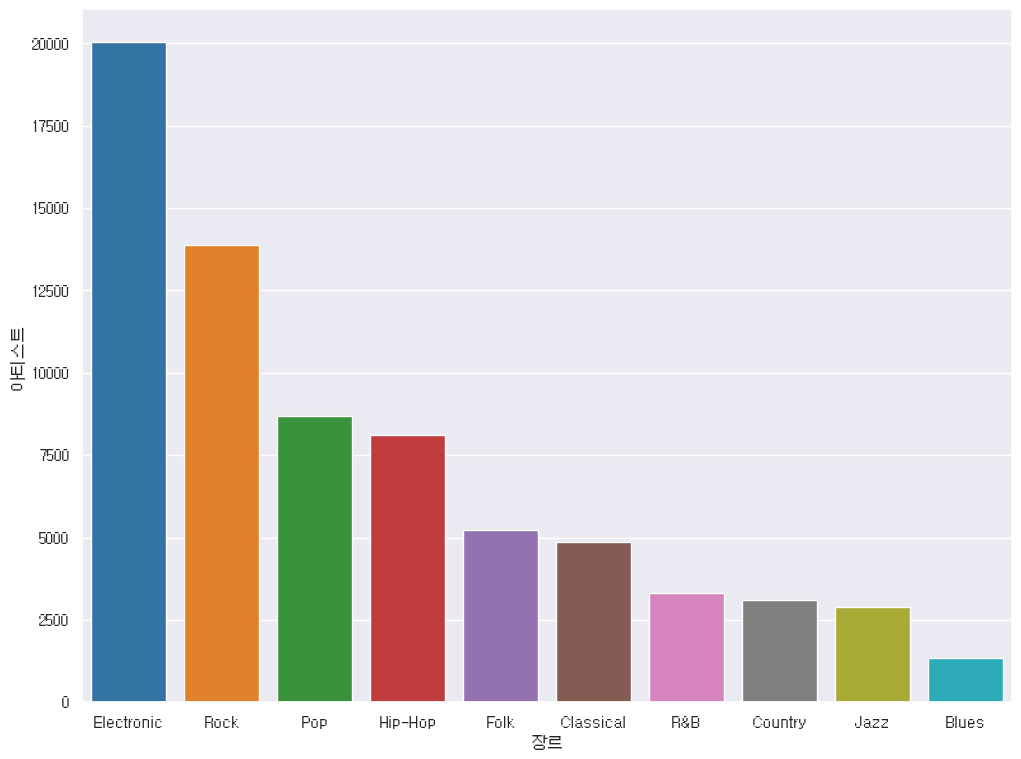
일단 장르별 팔로워 수는 일렉트로닉이랑 락이 많구만... 인기도도 또이또이다.
# 장르별, 팔로우 그룹별 시각화
genre_follower_hist = artist_df.groupby(['main_genre','follower_group'], observed=True)['id'].size().unstack()
# 정규화
genre_norm = genre_follower_hist.div(genre_follower_hist.sum(axis=1), axis=0)
# 시각화
genre_norm.plot(kind='barh', stacked=True, figsize=(12, 8), colormap='viridis')
plt.title('장르별 인기도 그룹 비중 (정규화)', fontsize=15)
plt.xlabel('비중 (Percentage)')
plt.ylabel('주요 장르')
plt.legend(title='인기도 그룹', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()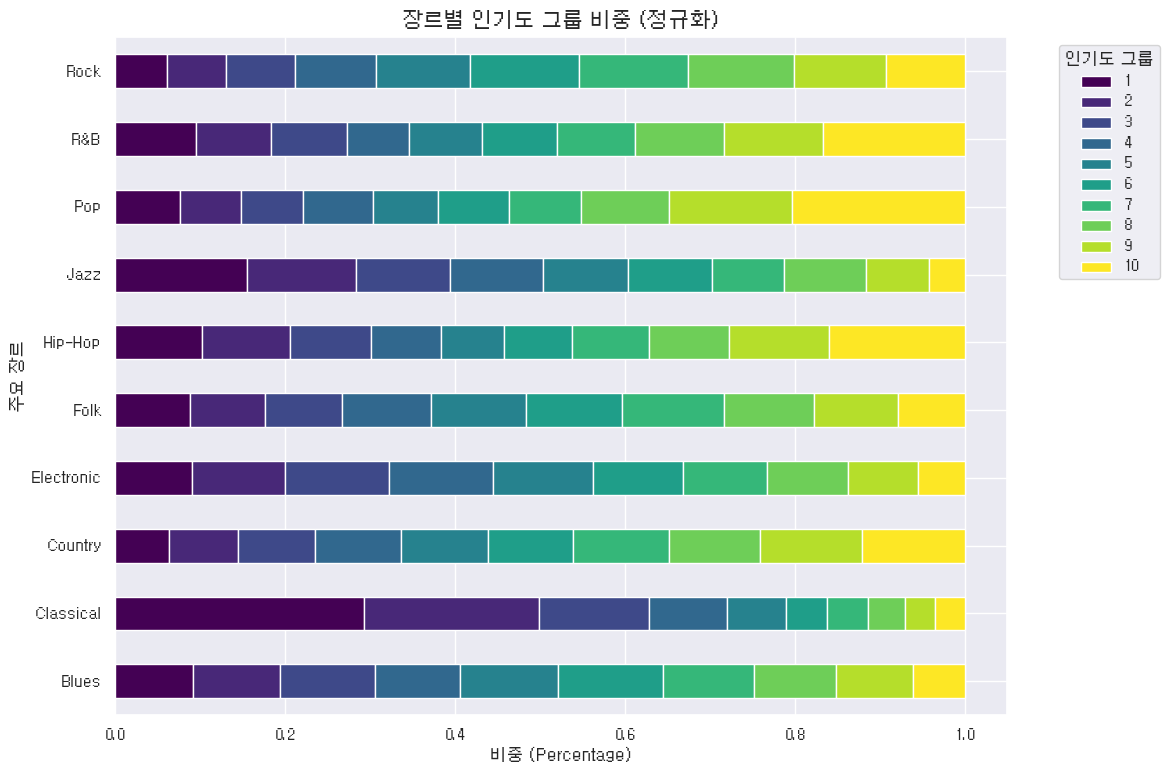
팔로워 수에 차이가 있으니까 정규화해서 비중을 봐야 한다. 그 포켓몬중에 지가르데라고 있는데, 얘가 퍼펙트폼으로 폼체인지를 할 때 피 회복이 되거든요? 신기하지 않습니까? 폼체인지를 하는데 피가 회복이 돼.
사실은 피 회복이 되는 게 아니라, HP 종족값이 늘어나서 최대 피통이 바뀐 것 때문에 체력이 회복되는 것처럼 보이는 것이다. 쉽게 말하자면 체력이 100인데 60을 잃으면 60%를 잃는거죠? 근데 체력이 200인데 60 잃은건 30%잖아요. 그런거임. 만 명 있는데 100명인거랑 1000명 있는데 100명 있는거랑은 엄연히 갭이 있기 때문에 정규화를 하는거라고 보시면 된다.
# 팔로워 상위 10%
top_10_percent = artist_df[artist_df['follower_group'] == 10]
top_10_genre = top_10_percent.groupby('main_genre').size()
top_10_genre_df = top_10_genre_s.reset_index()
top_10_genre_df.columns = [*top_10_genre_df.columns[:-1], 'artist_count']
top_10_genre_s = top_10_genre_df.sort_values('artist_count')
sns.barplot(data=top_10_genre_df, x='main_genre', y='artist_count', hue='main_genre', legend=False)
plt.xlabel('장르')
plt.ylabel('아티스트 수')
plt.show()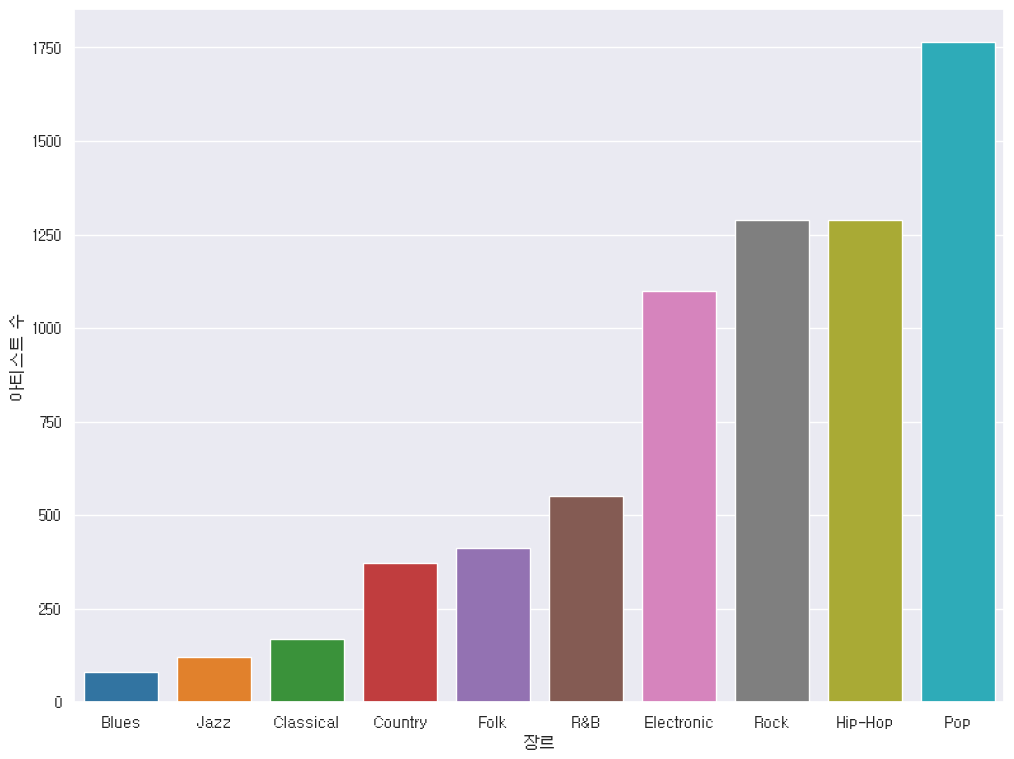
아, 참고로 테일러 스위프트도 팝에 있습니다. 시런좌도 있음. 스바 엔딩 크레딧곡 셀레스티얼 들어보십쇼.
노래 분석
그 우리 노래 연도 10틱으로 나눈거 있죠? 연도별로도 나눴음.
# 년도가 10년단위라서... 임시로 갑니다. 김람다씨!
song_df['Era_year'] = song_df['year'].apply(lambda x: f"{(int(x) // 10) * 10}s")그니까 1990년에 발매된 노래나 1980년에 발매된 노래나 다 1900s로 갑니다.
song_df.groupby(['Era_year','Era']).size().unstack()세로로 길어서 언스택했더니 무슨 거리행렬마냥 돼버렸네.

봐봐요. 거리행렬이지. 주대각선에만 있어. …근데 이거 100년 기준인데 왜 이렇게 된 거임?
# 년도가 10년단위라서... 임시로 갑니다. 김람다씨!
song_df['Era_year'] = song_df['year'].apply(lambda x: f"{(int(x) // 100) * 100}s")이 에미나이 이거 찰떡같이 말해도 개떡같이 알아듣는구만기래.

의도는 이거였음.
시대와 시대
plt.figure(figsize=(10, 6))
# 1900s vs 2000s 인기도 분포 비교
sns.boxplot(data=song_df, x='Era_year', y='popularity', hue='Era_year', palette='Set2', legend=False)
plt.title('20세기 vs 21세기 곡 인기도 분포 비교', fontsize=16)
plt.show()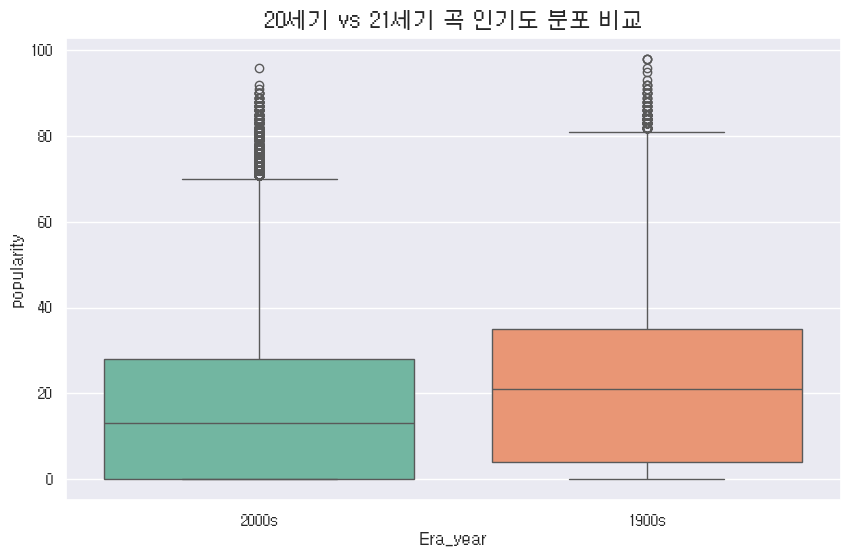
최신곡이라고 무조건 인기가 있는 건 아니기에… 뭐 요즘 레트로 열풍 이런것도 불고 있잖습니까. 근데… 솔직히 저 이상치 뭔지 궁금하지 않아요?
song_df.query('popularity > 80 and Era_year == "1900s"').sort_values('popularity', ascending=False).head()
솔직히 머라이어 캐리는 인정해야죠들. 우리나라에는 장범준의 벚꽃연금이 있다면 캐리언니는 크리스마스 연금 받는 분이심. 크리스마스마다 해동하잖음 ㅇㅇ
song_df.query('popularity > 80 and Era_year == "2000s"').sort_values('popularity', ascending=False).head()
역쉬 캐롤이 1위다. 근데 캐리누님이 근소하게 인기도는 더 높음. 아 얼려놨다가 겨울마다 해동한다니깐 그냥반은.
1990년대 띵곡들
song_1990 = song_df.query('Era_year == "1900s"')
era_boss_songs = song_1990.loc[song_1990.groupby('Era', observed=True)['popularity'].idxmax()]
display(era_boss_songs[['Era', 'artists', 'name', 'popularity']].sort_values('Era'))
진짜 궁금해서 물어보는건데… 50년대 이전 노래는 어떻게 찾은거임?
plt.figure(figsize=(12, 8))
# 20세기 곡들의 댄스빌리티와 에너지 관계도
sns.scatterplot(data=song_1990, x='danceability', y='energy', hue='popularity', size='popularity', alpha=0.5, sizes=(20, 200))
# 인기도 상위 5개 곡에 이름표 달아주기
for i in range(5):
target = era_boss_songs.iloc[i]
plt.text(target['danceability']+0.01, target['energy']+0.01, target['name'],
fontsize=10, weight='bold')
plt.title('20세기 띵곡들의 오디오 특징 분포', fontsize=16)
plt.show()
이거 저기 친구네 실험실 가서 현미경 빌려와야것는디?
# 인기도 80 이상만 명확하게 표시
top_classics = song_1990[song_1990['popularity'] >= 80]
plt.figure(figsize=(12, 8))
# 전체 배경은 연하게
sns.scatterplot(data=song_1990, x='danceability', y='energy', color='lightgrey', alpha=0.1)
# 띵곡들만 진하게
sns.scatterplot(data=top_classics, x='danceability', y='energy',
hue='popularity', size='popularity', palette='rocket', sizes=(50, 300))
plt.title('1990년대의 띵곡')
plt.show()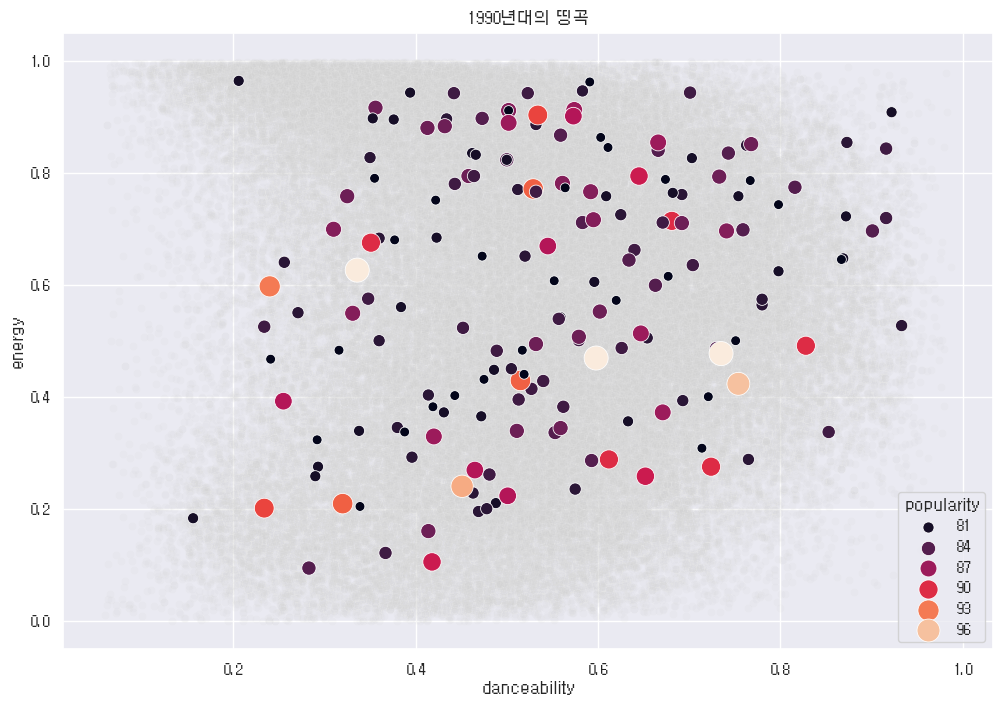
연한 놈이 범인이여. 개인적으로 이런 그래프는 마그마나 비리디스보단 블루스, 그레이스같은 단색이 더 무난한 것 같다.
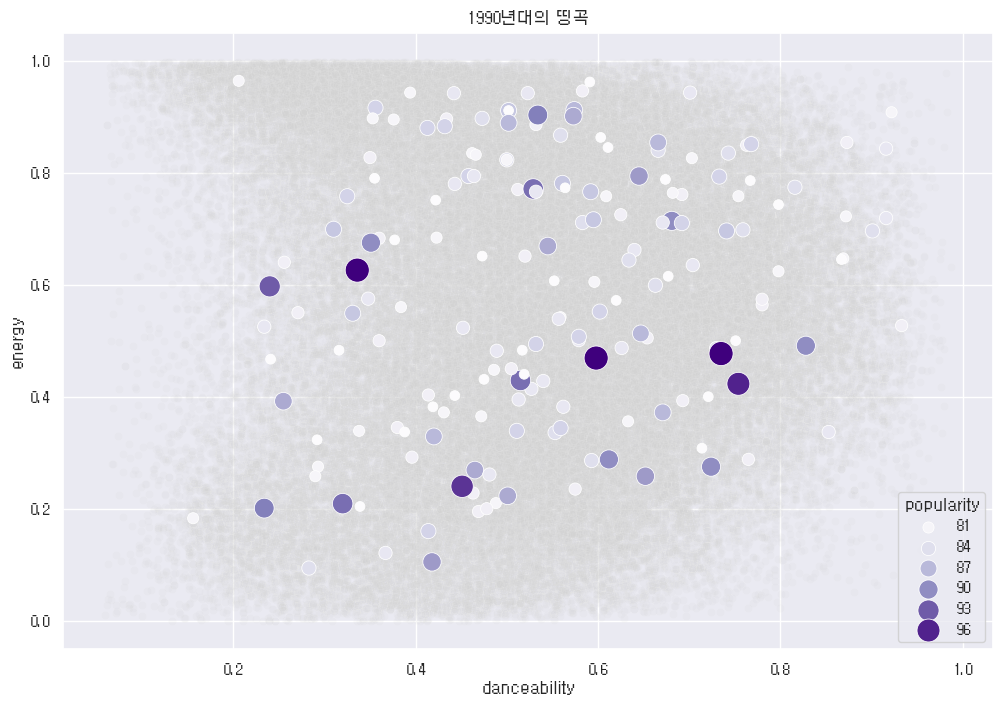
보라색이 있었으면 말을 하지 그래... 아무튼 여러분들은 히트맵이나 이런 산점도 그릴때 가급적 단색 쓰세요. 극단적인 변화량을 보여주고 싶으면 쿨웜이나 아이스파이어도 좋긴 한데 색깔 여러개면 눈뽕옴.
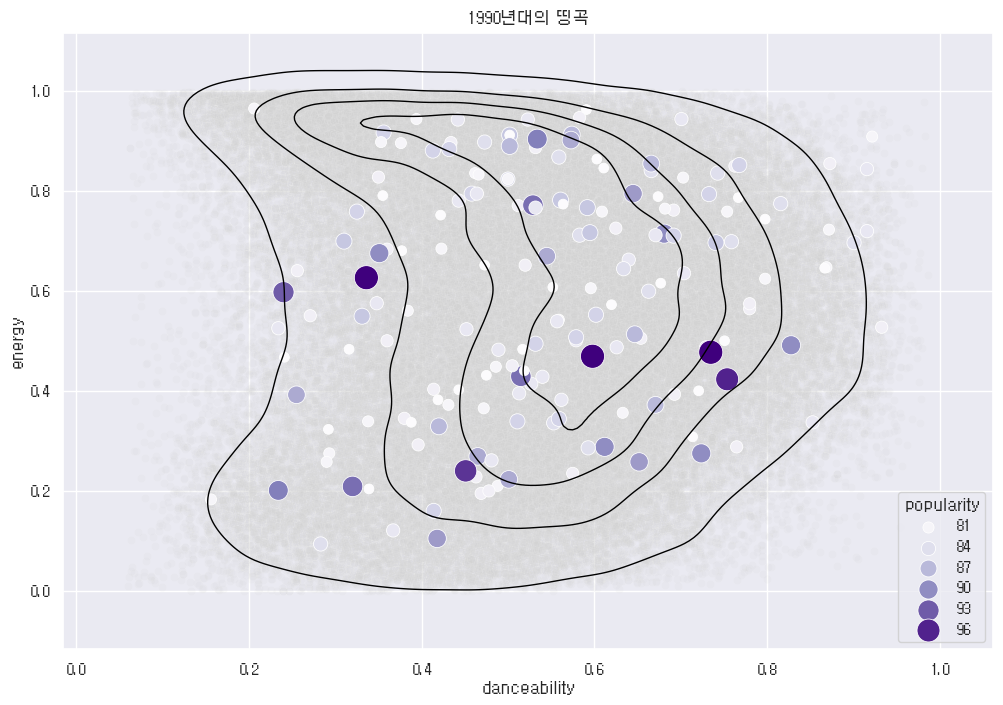
이건 KDE 등고선 추가 버전. 이걸 2000년대 곡들에도 할거다.
2000년대 띵곡들
song_2000 = song_df.query('Era_year == "2000s"')
era_boss_songs = song_2000.loc[song_2000.groupby('Era', observed=True)['popularity'].idxmax()]
display(era_boss_songs[['Era', 'artists', 'name', 'popularity']].sort_values('Era'))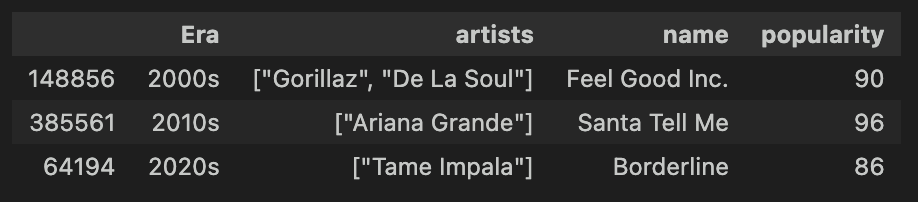
스포티파이는 빨리 일본곡 차트를 내놓아라. (다 모름)
# 인기도 80 이상만 명확하게 표시
top_classics = song_2000[song_2000['popularity'] >= 80]
plt.figure(figsize=(12, 8))
# KDE Plot (밀도 등고선) 추가
sns.kdeplot(data=song_2000, x='danceability', y='energy', levels=5, color="black", linewidths=1)
# 전체 배경은 연하게
sns.scatterplot(data=song_2000, x='danceability', y='energy', color='lightgrey', alpha=0.1)
# 띵곡들만 진하게
sns.scatterplot(data=top_classics, x='danceability', y='energy',
hue='popularity', size='popularity', palette='Purples', sizes=(50, 300))
plt.title('2000년대의 띵곡')
plt.show()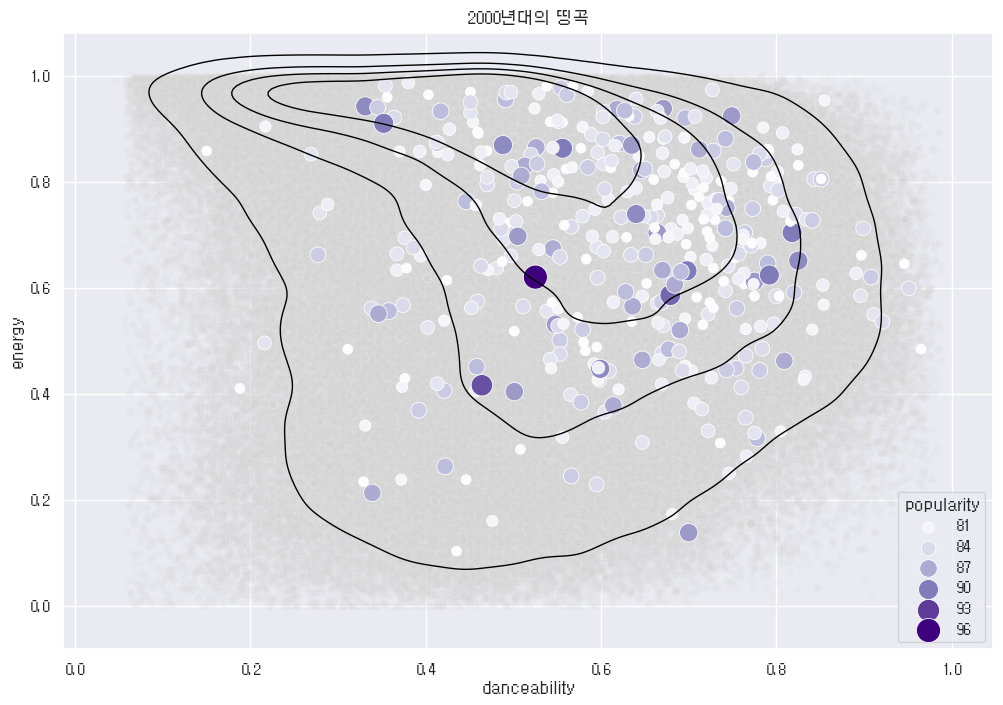
2000년대는 좀 더 등고선이 위로 올라간 느낌이다. 근데 이거 왜케 오래걸림?
아티스트별 띵곡 찾기
마이클 잭슨
# 구조된 마이클 잭슨 곡의 '민낯' 공개
mj_the_one = song_df[song_df['artists'].str.contains('Michael Jackson', case=False, na=False)].sort_values('popularity', ascending=False)
# 데이터 수치 확인 (NanumSquare 폰트로 출력!)
display(mj_the_one[['name', 'year', 'popularity', 'danceability', 'energy', 'valence']][0:5])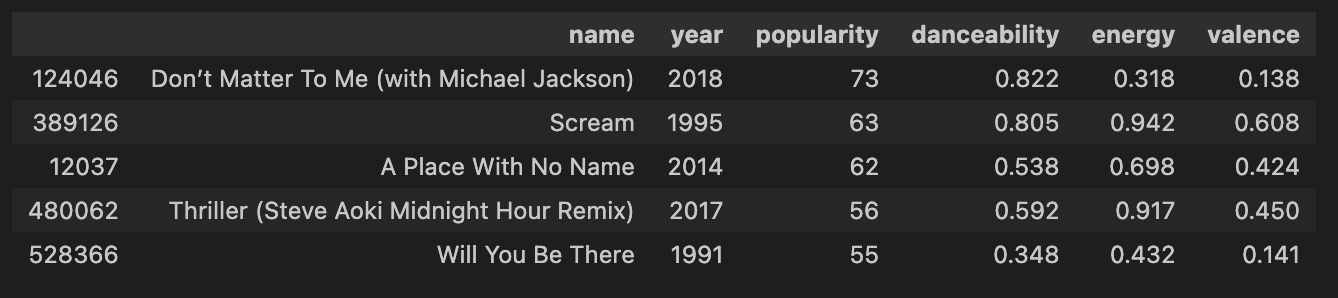
아 나도 마잭은 알아요 이 사람들아.
에드시런
# 에드시런 찾아 삼만리
mj_the_one = song_df[song_df['artists'].str.contains('Ed Sheeran', case=False, na=False)].sort_values('popularity', ascending=False)
# 데이터 수치 확인 (NanumSquare 폰트로 출력!)
display(mj_the_one[['name', 'year', 'popularity', 'danceability', 'energy', 'valence']][0:5])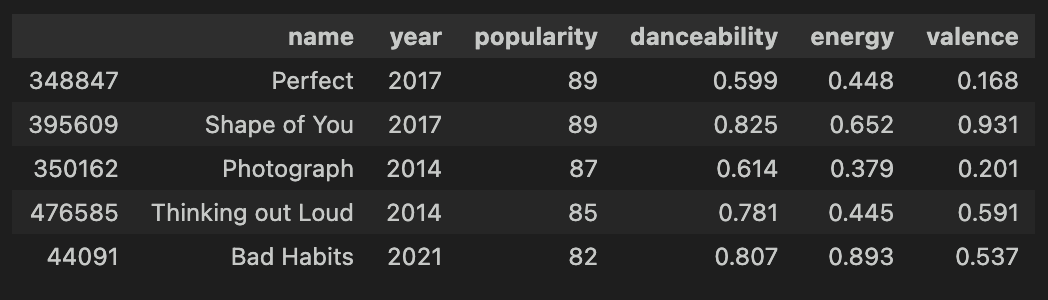
셀레스티얼은 밀렸군… 근데 shape of you도 좋음. 셀레스티얼은 스칼렛/바이올렛 엔딩 크레딧이기도 하고, 이 곡이 본가에 최초로 삽입된 '보컬 있는' 곡입니다. 기적은 가사는 있는데 보컬이 없음.
BTS
# 방탄 월클 맞다
mj_the_one = song_df[song_df['artists'].str.contains('BTS', case=False, na=False)].sort_values('popularity', ascending=False)
# 데이터 수치 확인 (NanumSquare 폰트로 출력!)
display(mj_the_one[['name', 'year', 'popularity', 'danceability', 'energy', 'valence']][0:5])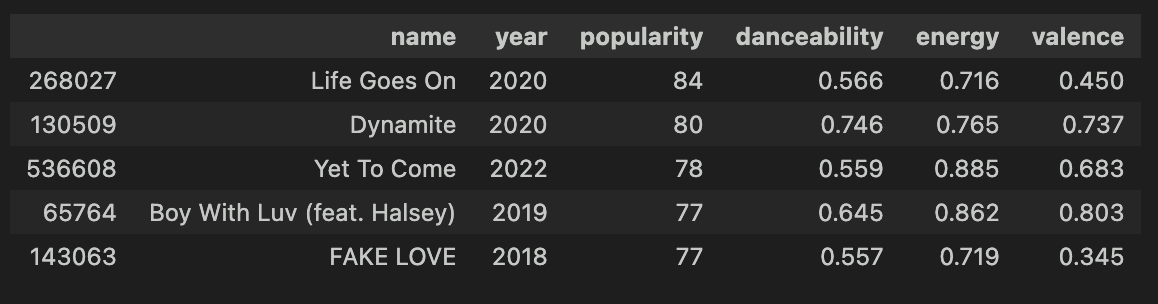
어… 저는 아미는 아닌데요… 걍 있나 해서 쳐봤더니 나왔어요… 다이너마이트 좋음. 라잇 업 라잌 라이크 다이나마잇 오오오
'Coding > EDA' 카테고리의 다른 글
| Post-COVID Video Games Worldwide (2021-2025) (0) | 2026.02.10 |
|---|---|
| 또 ChEMBL을 털어보았다 (0) | 2026.01.28 |
| 캐글 EDA-마! 서퍼티파이! (0) | 2026.01.19 |
| 그냥 해보는 ChEMBL EDA (0) | 2026.01.15 |
| 캐글 EDA-Video game sales (0) | 2026.01.09 |