이걸 근데 카테고리를 만들어야될지는 모르겠음… 이걸 매일 할 것 같지는 않고…
켐블서 특정 분자나 질환 치면 관련 화합물이 쭈루룩 나옵니다. 그거갖고 한거임.
거 정보좀 봅시다
df.shape()
(63, 29)켐블 데이터 특: 칼럼 엄청 많음
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 63 entries, 0 to 62
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ChEMBL ID 63 non-null object
1 Name 62 non-null object
2 Synonyms 59 non-null object
3 Type 63 non-null object
4 Max Phase 59 non-null float64
5 Molecular Weight 63 non-null float64
6 Targets 40 non-null float64
7 Bioactivities 40 non-null float64
8 AlogP 63 non-null float64
9 Polar Surface Area 63 non-null float64
10 HBA 63 non-null int64
11 HBD 63 non-null int64
12 #RO5 Violations 63 non-null int64
13 #Rotatable Bonds 63 non-null int64
14 Passes Ro3 63 non-null object
15 QED Weighted 63 non-null float64
16 Aromatic Rings 63 non-null int64
17 Structure Type 63 non-null object
18 Inorganic Flag 63 non-null int64
19 Heavy Atoms 63 non-null int64
20 Np Likeness Score 63 non-null float64
21 Molecular Formula 63 non-null object
22 Smiles 63 non-null object
23 Inchi Key 63 non-null object
24 Inchi 63 non-null object
25 Withdrawn Flag 63 non-null bool
26 Orphan 63 non-null int64
27 Records Key 63 non-null object
28 Records Name 63 non-null object
dtypes: bool(1), float64(8), int64(8), object(12)
memory usage: 14.0+ KB일단 여기서 미리 말하자면, NaN이 꽤 있는데 안채웠다. 왜요? 없어서 못 채웁니다. 임상(Max Phase)가 4.0이 아닌 약물들은 대부분 검색도 빡세고 켐블 최신 데이터까지 뒤져봤지만 역시나 NaN이었거든…
df.describe()
Max Phase Molecular Weight Targets Bioactivities AlogP Polar Surface Area HBA HBD #RO5 Violations #Rotatable Bonds QED Weighted Aromatic Rings Inorganic Flag Heavy Atoms Np Likeness Score Orphan
count 59.000000 63.000000 40.000000 40.00000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000 63.000000
mean 2.474576 286.804603 61.400000 282.35000 3.535079 48.665238 2.317460 0.968254 0.063492 3.984127 0.803175 1.841270 -0.063492 19.571429 -0.363492 -0.063492
std 1.164947 64.184537 87.147914 691.58282 0.694833 11.659890 1.044577 0.567060 0.245805 1.539712 0.097299 0.676956 0.245805 3.509040 0.536603 0.245805
min -1.000000 206.280000 1.000000 1.00000 2.100000 29.540000 1.000000 0.000000 0.000000 2.000000 0.490000 1.000000 -1.000000 15.000000 -1.510000 -1.000000
25% 2.000000 248.805000 2.000000 5.75000 3.070000 37.300000 1.000000 1.000000 0.000000 3.000000 0.755000 1.000000 0.000000 18.000000 -0.785000 0.000000
50% 2.000000 266.300000 8.500000 16.00000 3.430000 49.850000 2.000000 1.000000 0.000000 4.000000 0.820000 2.000000 0.000000 19.000000 -0.420000 0.000000
75% 4.000000 300.045000 102.750000 239.75000 3.825000 54.485000 3.000000 1.000000 0.000000 4.000000 0.865000 2.000000 0.000000 21.000000 0.070000 0.000000
max 4.000000 558.640000 375.000000 4089.00000 5.880000 86.630000 5.000000 3.000000 1.000000 9.000000 0.940000 3.000000 0.000000 33.000000 0.920000 0.000000여기 있다고 다 수치형 아님. Max Phase도 엄밀히 말하자면 값만 숫자지 사실상 범주형이다.
ChEMBL ID Name Synonyms Type Passes Ro3 Structure Type Molecular Formula Smiles Inchi Key Inchi Records Key Records Name
count 63 62 59 63 63 63 63 63 63 63 63 63
unique 63 62 59 1 2 1 53 63 63 63 63 63
top CHEMBL253765 (R)-SUPROFEN CLIPROFEN|CLIPROFENE|CLIPROFENO|R-25,160|R-25160 Small molecule N MOL C14H12O3S C[C@@H](C(=O)O)c1ccc(C(=O)c2cccs2)cc1 MDKGKXOCJGEUJW-SECBINFHSA-N InChI=1S/C14H12O3S/c1-9(14(16)17)10-4-6-11(7-5... ['SID11112759', '212, suprofen (R)', 'Suprofen... ['SID11112759', '(R)-2-(4-(thiophene-5-carbony...
freq 1 1 1 63 61 63 3 1 1 1 1 1값이 숫자가 아닌 애들은 이쪽.
df.isna().sum()
ChEMBL ID 0
Name 1
Synonyms 4
Type 0
Max Phase 4
Molecular Weight 0
Targets 23
Bioactivities 23
AlogP 0
Polar Surface Area 0
HBA 0
HBD 0
#RO5 Violations 0
#Rotatable Bonds 0
Passes Ro3 0
QED Weighted 0
Aromatic Rings 0
Structure Type 0
Inorganic Flag 0
Heavy Atoms 0
Np Likeness Score 0
Molecular Formula 0
Smiles 0
Inchi Key 0
Inchi 0
Withdrawn Flag 0
Orphan 0
Records Key 0
Records Name 0
dtype: int64아 저 바이오액티비티스 결측값인 애들 확인해볼걸..
df.head()
ChEMBL ID Name Synonyms Type Max Phase Molecular Weight Targets Bioactivities AlogP Polar Surface Area ... Heavy Atoms Np Likeness Score Molecular Formula Smiles Inchi Key Inchi Withdrawn Flag Orphan Records Key Records Name
0 CHEMBL253765 (R)-SUPROFEN NaN Small molecule NaN 260.31 12.0 15.0 3.17 54.37 ... 18 -0.81 C14H12O3S C[C@@H](C(=O)O)c1ccc(C(=O)c2cccs2)cc1 MDKGKXOCJGEUJW-SECBINFHSA-N InChI=1S/C14H12O3S/c1-9(14(16)17)10-4-6-11(7-5... False -1 ['SID11112759', '212, suprofen (R)', 'Suprofen... ['SID11112759', '(R)-2-(4-(thiophene-5-carbony...
1 CHEMBL2104170 CLIPROFEN CLIPROFEN|CLIPROFENE|CLIPROFENO|R-25,160|R-25160 Small molecule 2.0 294.76 NaN NaN 3.82 54.37 ... 19 -1.23 C14H11ClO3S CC(C(=O)O)c1ccc(C(=O)c2cccs2)c(Cl)c1 NLGUJWNOGYWZBI-UHFFFAOYSA-N InChI=1S/C14H11ClO3S/c1-8(14(17)18)9-4-5-10(11... False 0 ['CLIPROFEN', 'CLIPROFEN'] ['CLIPROFEN', 'CLIPROFEN']
2 CHEMBL2107442 LOBUPROFEN LOBUPROFEN|LOBUPROFENE|LOBUPROFENO Small molecule 2.0 429.00 NaN NaN 5.01 32.78 ... 30 -1.12 C25H33ClN2O2 CC(C)Cc1ccc(C(C)C(=O)OCCN2CCN(c3cccc(Cl)c3)CC2... JFGXBHHLHQAGRR-UHFFFAOYSA-N InChI=1S/C25H33ClN2O2/c1-19(2)17-21-7-9-22(10-... False 0 ['LOBUPROFEN'] ['LOBUPROFEN']
3 CHEMBL4297164 XIMOPROFEN XIMOPROFEN|XIMOPROFENE|XIMOPROFENO Small molecule 2.0 261.32 1.0 1.0 3.36 69.89 ... 19 0.16 C15H19NO3 CC(C(=O)O)c1ccc(C2CCCC(=NO)C2)cc1 IQPPOXSMSDPZKU-UHFFFAOYSA-N InChI=1S/C15H19NO3/c1-10(15(17)18)11-5-7-12(8-... False 0 ['Ximoprofen', 'XIMOPROFEN'] ['Ximoprofen', 'XIMOPROFEN']
4 CHEMBL2107432 LOSMIPROFEN LOSMIPROFEN|LOSMIPROFENE|LOSMIPROFENO Small molecule 2.0 318.76 NaN NaN 3.73 63.60 ... 22 -0.76 C17H15ClO4 Cc1c(OC(C)C(=O)O)cccc1C(=O)c1ccc(Cl)cc1 JQYJAGNNCNBFRM-UHFFFAOYSA-N InChI=1S/C17H15ClO4/c1-10-14(16(19)12-6-8-13(1... False 0 ['LOSMIPROFEN'] ['LOSMIPROFEN']이건 그냥 아 이렇게 있구나만 보십쇼.
df.column
Index(['ChEMBL ID', 'Name', 'Synonyms', 'Type', 'Max Phase',
'Molecular Weight', 'Targets', 'Bioactivities', 'AlogP',
'Polar Surface Area', 'HBA', 'HBD', '#RO5 Violations',
'#Rotatable Bonds', 'Passes Ro3', 'QED Weighted', 'Aromatic Rings',
'Structure Type', 'Inorganic Flag', 'Heavy Atoms', 'Np Likeness Score',
'Molecular Formula', 'Smiles', 'Inchi Key', 'Inchi', 'Withdrawn Flag',
'Orphan', 'Records Key', 'Records Name'],
dtype='object')보다보면 여기서 견적 나옴.
전처리
위에도 말했지만 결측값 이거는 우리가 못때워요... 몰라 안나와... 그래서 여기서는 범주화만 할 거다.
# 분자량이 500보다 크면 헤비 아니면 라이트
data_df['Moecular_classification'] = data_df['Molecular Weight'].apply(lambda x: 'Heavy' if x > 500 else 'Light')아니 왜 하필 500이죠? 리핀스키의 5대 규칙에서 마지노선을 500으로 정했음. 저 람다 뭐죠? 아니 칼럼 둘로 나누는데 굳이 기명함수가 필요한가 해서 람다식 씀. 범주가 다 이래요.
# 4: Approved/3~0: Clinical/-1: Failed
data_df['Status'] = data_df['Max Phase'].map({4: 'Approved', 3: 'Clinical', 2: 'Clinical', 1: 'Clinical', 0: 'Clinical', -1: 'Failed'})
# 아니 맵합수가 왜 여기서나는 백준 풀 때나 보던 맵이 나와서 당황했고… 이건 Max phase에 따라 범주화한건데, Max Phase가 4면 승인된(시장에 발은 들인)거고, 3~0이면 임상 단계인거고, -1이면 엎은거다.
본게임은 지금부터다
임상 단계별 분자량 평균
data_df.groupby('Status')['Molecular Weight'].mean() # 평균Status
Approved 279.101176
Clinical 293.348500
Failed 272.860000
Name: Molecular Weight, dtype: float64근데 우리가 얘만 봐서는 이게 분포가 어떤지 몰라요. 그니까 빡스플롯을 그려보자 이거다. 근데 이제 스웜플롯을 곁들인.
# boxplot
sns.boxplot(data_df, x = 'Status', y = 'Molecular Weight', hue = 'Status')
sns.swarmplot(data=data_df, x='Status', y='Molecular Weight', color='red', alpha=0.5)
plt.title('Molecular Weight by Status')
plt.show()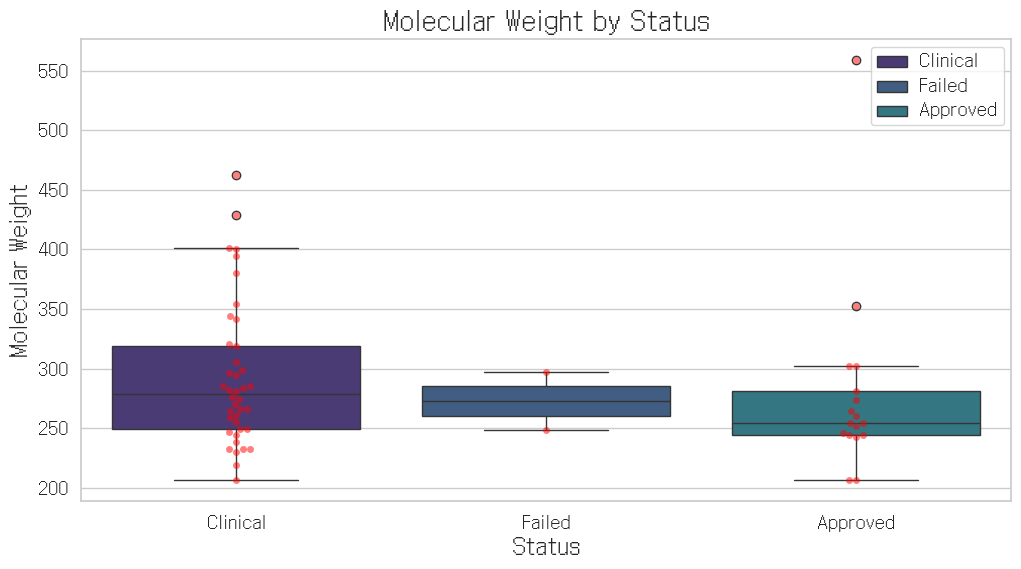
보니까 clinical에 있는 이상치들은 그래도 500은 안 넘었는데, 저기 500 넘은 놈이 하나 있네? 너 누구야!
범인은 FENOPROFEN CALCIUM이라는 놈인데, 얘는 그 자체로는 분자량이 그렇게 크지 않다. 근데 왜 500이 넘는데요? 쟤가 구조상 카복실산(COOH)이 달려있는데 카복실산이 음전하거든요? 그니까 단독으로 두면 안정하지 아니할 거 아니예요. 그래서 칼슘이랑 걔랑 뭔 상관이냐고? 칼슘이 2가 양이온이니까 저 페노프로펜이라는 친구를 양 옆구리에 하나씩 끼고 있는거다.
clinical에 있는 이상치들은 다 뭘 붙여서 몸집이 커진 케이스.
Bioactivities
약을 먹으면 우리 몸에 들어와서 일을 하겠죠? 그 활성 정도를 말한다.
data_df.groupby('Status')['Bioactivities'].mean() # 평균Status
Approved 680.666667
Clinical 53.052632
Failed 24.500000
Name: Bioactivities, dtype: float64이상하다? 쟤 평균이 왜 저렇게 높지? 결측값이 다 밑에 몰렸나? 그게 아님.
# boxplot
sns.boxplot(data_df, x = 'Status', y = 'Bioactivities', hue = 'Status')
sns.swarmplot(data=data_df, x='Status', y='Bioactivities', color='red', alpha=0.5)
plt.title('Bioactivities by Status')
plt.show()
저 봐요 저기 이상치 있는거. 저것때문에 평균 망한거임. 그래서 쟤는 뭔데 활성도가 저렇게 높아요? 이부프로펜 본인이요.
# 맨 휫흐니 검정을 할거예요
# 얘네는 수가 적어서 t-test 못해요
clinical_vals = data_df[data_df['Status'] == 'Clinical']['Bioactivities'].dropna() # 클리니컬
failed_vals = data_df[data_df['Status'] == 'Failed']['Bioactivities'].dropna() # 엎음
u_stat, p_val = stats.mannwhitneyu(clinical_vals, failed_vals, alternative='two-sided')
print(f"Mann-Whitney U statistic: {u_stat}")
print(f"P-value: {p_val}")
if p_val < 0.05:
print("결과: 두 그룹 간에 통계적으로 유의미한 차이가 있습니다! (다른 놈임)")
else:
print("결과: P-value가 0.05보다 큽니다. 두 그룹은 통계적으로 '그놈이 그놈'입니다.")저 옆에놈들이 진짜로 또이또이인지 통계검정을 해 볼건데, 맨-휘트니 검정을 할 거다. 아니 t-test 어디감? t-test를 하려면 표본이 충분히 크거나 정규성을 만족해야되는데 Failed에 딸랑 두개있음. 그 크기 마지노선이 30임다.
Mann-Whitney U statistic: 12.0
P-value: 0.43372561703125134
결과: P-value가 0.05보다 큽니다. 두 그룹은 통계적으로 '그놈이 그놈'입니다.그놈이 그놈이래.
AlogP
data_df.groupby('Status')['AlogP'].mean() # 평균Status
Approved 3.369412
Clinical 3.675500
Failed 3.355000
Name: AlogP, dtype: float64얘는 뭐냐면 이 분자가 얼마나 기름진가의 지표이다. 얘도 5 넘어가면 안된다.
# boxplot
sns.boxplot(data_df, x = 'Status', y = 'AlogP', hue = 'Status')
sns.swarmplot(data=data_df, x='Status', y='AlogP', color='red', alpha=0.5)
plt.title('AlogP by Status')
plt.show()
엎은 애들이랑 승인됨에는 없는데 임상 진행중인 애들중에 이상치가 꽤 보인다. 저 중에서 하나는 동물용 소염진통제, 하나는 항진균제(바르는거)이고 나머지 두 개는 정보가 없음.
Withdrawn Flag
모든 약에는 부작용이 있다. 이 플래그는 부작용 관련된건데... 아니 근데 다 부작용이 있는데 저 플래그는 뭐임? 그 부작용에도 '정도'가 있어요. 그 부작용이 아 이거 터지면 사람 죽는다 내지는 와 이거 심각한데 수준이면 저 플래그가 선다고 보면 된다. 대표적인 예시가 탈리도마이드.
- Benoxaprofen: 간 괴사, 광과민성, 담즙정체성 황달
- Suprofen: 신장 독성 (옆구리 통증 증후군)
- Pirprofen: 심각한 간독성
- Indoprofen: 위장관 출혈 및 발암성 의혹
이런 이유로 승인됐다가 시장에서 빠졌다고 보면 된다. 얘들도 나중에 다른 쓸모가 발견된다면 다시 쓰일지는 모르겠지만… 탈리도마이드도 다른 쓸모를 찾았음.
HBA, HBD
# FacetGrid를 사용해 Status별로 나눠서 보기
g = sns.FacetGrid(data_df, col="Status", height=4, aspect=1.2, col_order=['Approved', 'Clinical', 'Failed'])
g.map_dataframe(sns.histplot, x="HBA", y="HBD", discrete=(True, True), cbar=True, cmap="YlGnBu")
g.set_axis_labels("HBA (Acceptors)", "HBD (Donors)")
g.set_titles("{col_name} Group")
plt.tight_layout()
plt.show()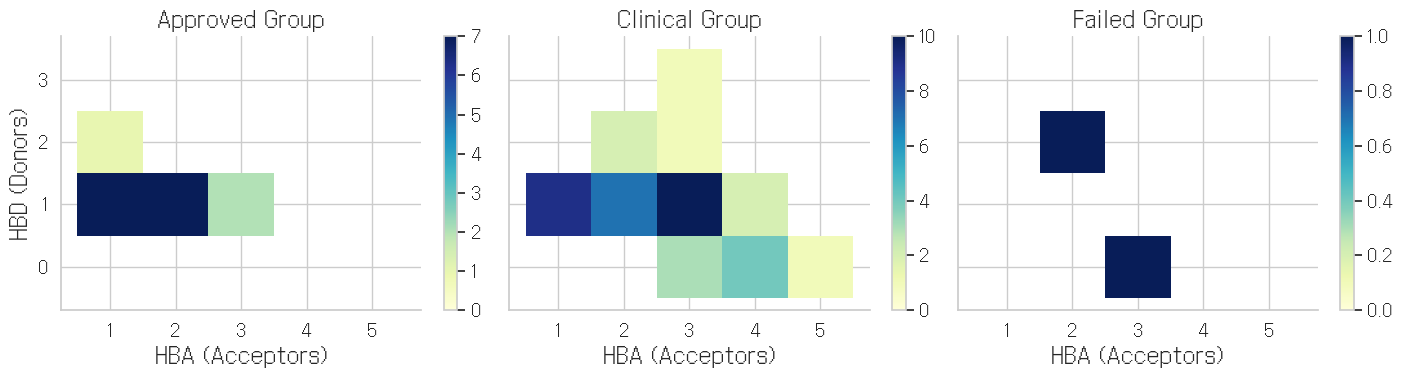
클리니컬은 뭔가 중구난방이구만. 참고로 둘다 5 넘어가면 안된다.
RO5 violation
data_df.groupby(['Status','#RO5 Violations']).size() # 분포 왜이래요Status #RO5 Violations
Approved 0 17
Clinical 0 36
1 4
Failed 0 2
dtype: int64이거 룰인데 어겨도 돼요? 라고 하실 수도 있는데 이걸 준수하면 좋은거지 뭔 법같은 게 아님. 당장 항체(주사형태)는 옛저녁에 RO5 위반했지만 잘 쓰고 있잖아요?
그래서 범인이 누구냐... 저기 AlogP 5 넘는 애들이요.
결론
1. 원조가 짱이다(이부프로펜 활성이 제일높음)
2. RO5를 위반하지 않더라도 부작용때문에 시장에서 퇴출될 수 있다. 승인되더라도 오래 살아남는 약은 없다.
3. 탈리도마이드같은 게 또 있었네.
'Coding > EDA' 카테고리의 다른 글
| Post-COVID Video Games Worldwide (2021-2025) (0) | 2026.02.10 |
|---|---|
| 또 ChEMBL을 털어보았다 (0) | 2026.01.28 |
| 캐글 EDA-마! 서퍼티파이! (2) (0) | 2026.01.20 |
| 캐글 EDA-마! 서퍼티파이! (0) | 2026.01.19 |
| 캐글 EDA-Video game sales (0) | 2026.01.09 |