

- R 배워보기-5. 데이터 불러오고 쓰기 2022.08.20
- 번외편-R로 미적분 하기 2022.08.20
- R 배워보기-4. 공식 2022.08.20
- R 배워보기-3. 문자열 2022.08.20
- R 배워보기-2. Numbers 2022.08.20
- R 배워보기-1. Basics 2022.08.20
- 정렬 알고리즘 2022.08.20
- 쿼리와 SQL 2022.08.20
- 지금까지 썼던 IDE&에디터 풀어봄 2022.08.20
- 백준 10989번 풀이 2022.08.20
read.csv()
data <- read.csv('/home/koreanraichu/Others/csv/Drug.csv')불러오는 거 성공은 했는데, 터미널에서 열었음(...)+SMILES 길이때문에 개 방대함으로 인해 결과 갭처 불가... 실화다.
> data=read.csv("http://www.cookbook-r.com/Data_input_and_output/Loading_data_from_a_file/datafile.csv")
> data
First Last Sex Number
1 Currer Bell F 2
2 Dr. Seuss M 49
3 Student <NA> 21웹에서 가져오는 것도 된다.
read.table()
data <- read.table('/home/koreanraichu/Others/csv/Drug.csv',header=FALSE,sep=",")헤더에 false를 줬더니 헤더가 가출한 상태로 온다. sep=","은 파이썬에도 비슷한 게 있음. (구분자 가르쳐주는 거)
> data=read.table("http://www.cookbook-r.com/Data_input_and_output/Loading_data_from_a_file/datafile.csv",strip.white=TRUE)
> data
V1 V2
1 First ,"Last","Sex","Number"
2 Currer ,"Bell","F",2
3 Dr. ,"Seuss","M",49
4 ,"Student",NA,21read.table()에 strip.white=TRUE를 주면...... 내가 뭘 잘못했길래 표가 이렇게 개판 오분전이 된 걸까...
file.choose()
> data<-read.csv(file.choose())
Enter file name: /home/koreanraichu/Others/csv/Drug.csv쿡북에는 Dialog 어쩌고 하던데 여는 리눅스+터미널크리로 직접 경로를 써야 한다. (아예 쓰라고 뜬다)
stringsAsFactor
솔직히 팩터가 뭔지는 모름.
data <- read.csv('/home/koreanraichu/Others/csv/Drug.csv',stringsAsFactors=FALSE)이렇게 가져오면 된다. strongsAsFactors는 옵션 이름)
> data <- read.csv('/home/koreanraichu/Others/csv/Drug.csv',stringsAsFactors=FALSE)
> str(data$CID)
int [1:17] 2244 1983 3672 6518 441300 71226662 6852395 65030 6918638 14982 ...
> str(data$SMILES)
chr [1:17] "CC(=O)OC1=CC=CC=C1C(=O)O" "CC(=O)NC1=CC=C(C=C1)O" ...> data <- read.csv('/home/koreanraichu/Others/csv/Drug.csv',stringsAsFactors=TRUE)
> str(data$CID)
int [1:17] 2244 1983 3672 6518 441300 71226662 6852395 65030 6918638 14982 ...
> str(data$SMILES)
Factor w/ 17 levels "C(C(CO[N+](=O)[O-])(CO[N+](=O)[O-])CO[N+](=O)[O-])O[N+](=O)[O-]",..: 8 6 9 1 5 10 7 16 3 11 ...위는 해당 옵션이 False일 때, 아래는 True일 때. 잘 보면 SMILES가 각각 chr와 factor로 다르다.
헐 근데 저 이거 안 주고 불러왔는데 망한듯... 아니 다시 불러오기 귀찮은데... 어쩌죠... 어 그럼
> data$SMILES = as.character(data$SMILES)
> str(data$SMILES)
chr [1:17] "CC(=O)OC1=CC=CC=C1C(=O)O" "CC(=O)NC1=CC=C(C=C1)O" ...단식이면 이거 주고
> stringcols=c("Name","Molecular.Weight")
> data[stringcols]=lapply(data[stringcols],as.character)뭉텅이면 이거 주면 된다. ($는 pandas에서 ['컬럼']과 같은 기능을 한다)
엑셀과 SPSS
엑셀... 나 여기 xls가 없음...
read.xls()아무튼 이걸로 읽는다.
library(foreign)
read.spss()SPSS 파일은 foreign이라는 라이브러리를 불러온 상태에서 읽어야 한다.
표 만드는건 왜 되는거지
> data=read.table('clipboard',header=TRUE)
경고메시지(들):
In read.table("clipboard", header = TRUE) :
'clipboard'에서 readTableHeader에 의하여 발견된 완성되지 않은 마지막 라인입니다
> data
size weight cost
1 small 5 6
2 medium 8 10
3 large 11 9클립보드에 있는 걸 불러오거나(물론 복사는 해야 한다)
> data2=read.table(stdin(),header=TRUE)
0: 1 2 3 4
1: 0 0 0 0
2: 0 0 0 0
3: 0 0 0 0
4:
> data2
X1 X2 X3 X4
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0입력하거나...
> print(data2,row.names=FALSE)
X1 X2 X3 X4
0 0 0 0
0 0 0 0
0 0 0 0행 이름 떼고 볼 수도 있다.
> write.csv(data,stdout(),row.names=FALSE)
"size","weight","cost"
"small",5,6
"medium",8,10
"large",11,9내 마음 속... 아니고... 하드... 아니고... 클립보드에 저(별)장 하고싶으면 이거 쓰자. 파일이요? 그건 이따 나와요.
source()
R 스크립트를 불러올 때 쓰는데 내 컴퓨터에 R 스크립트가 없다.
setwd('/home/username/desktop/rcode') # 소스가 있는 디렉토리로 가서
source('analyze.r') # 실행한다그렇다고 합니다.
write.csv()
> setwd('/home/koreanraichu')
> write.csv(data,"data.csv")저거 안 해두면 대체 파일이 죄다 어디로 가는거냐... (setwd()는 work directory를 설정할 때 쓴다)

아무튼 저장된 거 맞다.
옵션으로 row.names=FALSE를 주면 행 이름이 빠지고, na=""를 주면 결측값을 공백으로 때운다. 잠깐 이거 다른걸로도 때울 수 있나?
> write.table(data, "data.csv", sep="\t", row.names=FALSE, col.names=FALSE)구분자도 지정 가능하다. (해당 코드에서는 탭으로 지정했고 저게 다 적용돼서 행렬 이름이 다 빠진다)
dump()
dump("data","data.Rdmpd") # 하나
dump(c("data","data2"),"data1.Rdmpd") # 뭉텅이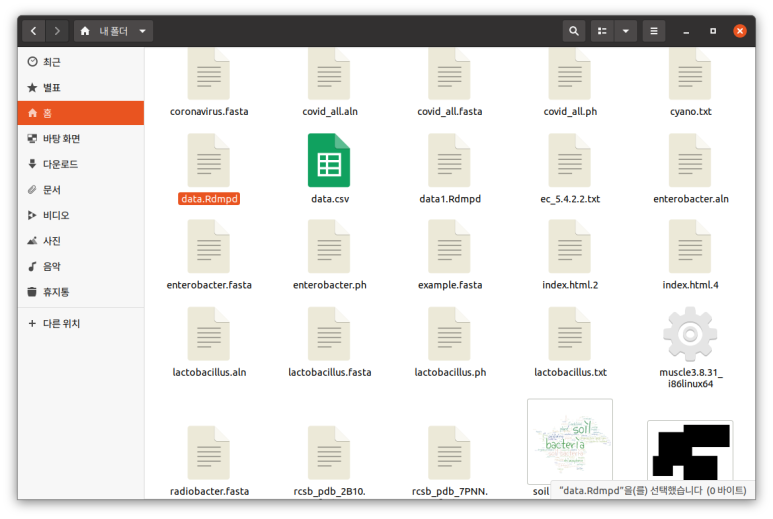
dump()를 이용해 Rdmpd로 저장한 결과.
saveRDS()
saveRDS("data","data.rds")
# ascii=TRUE 옵션을 주면 아스키 포맷이 된다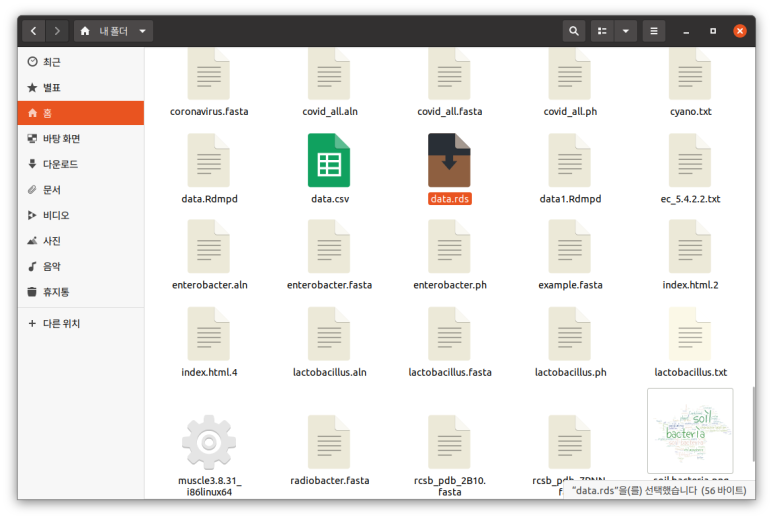
saveRDS()를 이용해 RDS format으로 저장한 결과. 참고로 저거 압축 관리자 소환된다. (그리고 압축 풀다가 에러났다)
save()
save(data,file="data.RData")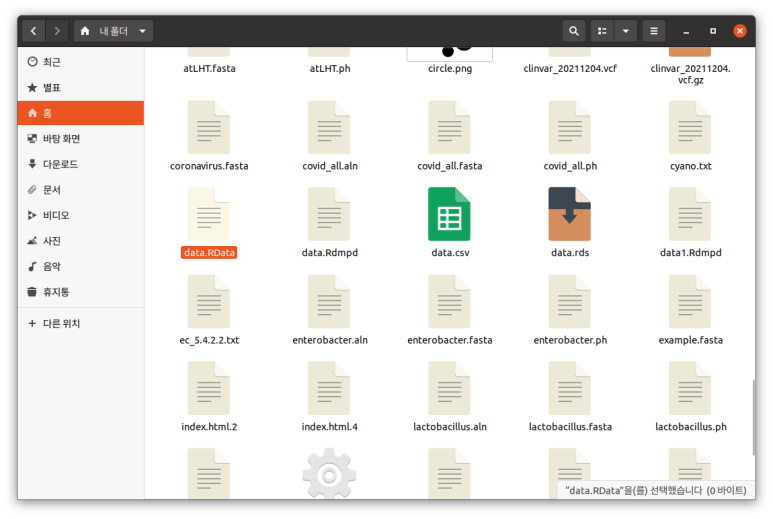
(추천 브금: 영탁-니가 왜 거기서 나와) R스튜디오: 불러놓고 뭔소리여
> save(data,file="data.RData",ascii=TRUE)Ascii 포맷으로 저장할거면 이거 쓰면 되고
save(data, data1, file="data.RData")여러 개 한꺼번에 쓸 거면 이거 쓰면 된다.
sink()
> sink('analysis-output.text')
> set.seed(1)
> x=rnorm(10,10,1)
> y=rnorm(10,11,1)
> cat(sprintf("x has %d elements:\n",length(x)))
> print(x)
> cat("y=",y,"\n")
> cat("----------\n")
> cat("T-test between x and y\n")
> cat("----------\n")
> t.test(x,y)
> sink()
# 여기까지가 일차적인 기록이다.
> sink('analysis-output.text',append=TRUE)
> cat("some more stuff here?")
> sink()
# append(내용 추가)한다는 모양.

오 쩐다 피보나치 수열도 저장 되나?
'Coding > R' 카테고리의 다른 글
| R 배워보기- 6.2. Manipulating data-Factors (0) | 2022.08.20 |
|---|---|
| R 배워보기- 6.1. Manipulating data-General (0) | 2022.08.20 |
| 번외편-R로 미적분 하기 (0) | 2022.08.20 |
| R 배워보기-4. 공식 (0) | 2022.08.20 |
| R 배워보기-3. 문자열 (0) | 2022.08.20 |
하는김에 어? 이거 되나? 해서 찾아봄.
미분
> f<-expression(a*x^5+b*x^2+c)
> D(f,"x")
a * (5 * x^4) + b * (2 * x)미분은 이런 식으로 한다. 근데 계산은 안 해준다. 믿고보는 알파신이 짱이다
> f<-expression(exp(x))
> D(f,"x")
exp(x)y=e^x를 미분하면 이게 정상이다. 으아아 미분했는데 왜 그대로야 정상입니다 손님
편미분 마려워요?
> f<-expression(x^2*y^2+2*x*y+y)
> D(f,'x')
2 * x * y^2 + 2 * y
# x로 미분해주세요
> D(f,'y')
x^2 * (2 * y) + 2 * x + 1
# y로 미분해주세요저 D에서 기호를 바꿔주면 알아서 편미분이 된단다. 위 코드는 각각 x로 한 번, y로 한 번 미분한 결과. (그러니까 어쨌든 한 번 미분했다)
> D(D(f,'x'),'y')
2 * x * (2 * y) + 2
# x로 미분하고 y로 미분하고이건 x로 미분한 다음 y로 미분한 것. ...이거 식으로 쓸 줄 아시는 분 제보 바랍니다. (이사람 미적 못함)
> f=expression(exp(x))
> D(f,'x')
exp(x)
> D(f,'y')
[1] 0y=e^x는 x가 아닌 다른 기호로 편미분하면 0이 된다. (미분 귀신에도 나왔다)
여러번 미분하기
> f<-expression(x^2)
> D(f,'x')
2 * x
> D(D(f,'x'),'x')
[1] 2이거 찾아보니까 함수 만들어놓고 쓰던데?
두 번 미분해서 저정도지 세번 네번 하려면 귀찮을 듯.
> f<-expression(5*x^5+3*x^3+2)
> D(f,"x")
5 * (5 * x^4) + 3 * (3 * x^2)
# 일계도함수
> D(D(f,"x"),"x")
5 * (5 * (4 * x^3)) + 3 * (3 * (2 * x))
# 의 일계도함수이렇게 한번 두번 하거나
> f=expression(5*x^7+3*x^4+2)
> D(f,"x")
5 * (7 * x^6) + 3 * (4 * x^3)
# 한 번 미분한 것
> ff=D(f,"x")
# 을 저장
> D(ff,"x")
5 * (7 * (6 * x^5)) + 3 * (4 * (3 * x^2))
# (마른세수)한번 미분한 것을 변수에 저장하고 또 미분하거나인데 계산은 안해준다.
그냥 울프램알파를 켜자.
적분
정적분
> f<-function(x) x^2+x
> integrate(f,0,1)
0.8333333 with absolute error < 9.3e-15integrate()는 범위를 지정해줘야 한다. 즉, 기본 옵션이 정적분이다.
> e<-function(x) exp(x)
> integrate(e,0,1)
1.718282 with absolute error < 1.9e-14근데 y=e^x가 적분해도 똑같음? ㄷㄷ
부정적분
library(Ryacas)
yac_str("Integrate(x) Exp(x)")
[1] "Exp(x)"Ryacas라는 패키지를 깔고 들어가야 한다. (install.packages("Ryacas") 다음에 library로 소환) 맨 윗줄에 library()는 파이썬으로 치자면 import ~와 같은 것.
> yac_str("Integrate(x) x^2")
[1] "x^3/3"저기 실례지만 적분상수는 어디 가출하셨나요? (원래 부정적분으로 y=x^2를 적분하면 x^3/3+C 가 된다. C=적분상수)
아 이상적분이요? 아이고 고급진거 물어보시네
> integrate(f,0,Inf)
Error in stats::integrate(...) : the integral is probably divergent이상적분이면 범위가 무한대까지인데 에러뜸... 이럴거면 인수에 0~Inf 왜 있냐...
'Coding > R' 카테고리의 다른 글
| R 배워보기- 6.1. Manipulating data-General (0) | 2022.08.20 |
|---|---|
| R 배워보기-5. 데이터 불러오고 쓰기 (0) | 2022.08.20 |
| R 배워보기-4. 공식 (0) | 2022.08.20 |
| R 배워보기-3. 문자열 (0) | 2022.08.20 |
| R 배워보기-2. Numbers (0) | 2022.08.20 |
공식 번외편도 따로 나갑니다.
as.formula()
y~x
y ~ x이놈은 문자고
as.formula("y~x")
y ~ x이놈은 공식이다.
뭔 차이인지는 모르겠다.
> measurevar="y"
> groupvars=c("x1","x2","x3")
paste(measurevar,paste(groupvars,collapse="+"),sep="=")
[1] "y=x1+x2+x3"이놈도 문자인데
as.formula(paste(measurevar, paste(groupvars, collapse=" + "), sep=" ~ "))
y ~ x1 + x2 + x3이놈은 공식이다.
역시 뭔 차이인지 모른다.
공식의 구조
t=y~x1+x2이렇게 공식을 만들어서 확인해보면(아, 참고로 <-나 =나 둘 다 된다)
str(t)
Class 'formula' language y ~ x1 + x2
..- attr(*, ".Environment")=<environment: R_GlobalEnv>랭귀지는 또 뭐여...
> f=as.formula(y~x^2)
> str(f)
Class 'formula' language y ~ x^2
..- attr(*, ".Environment")=<environment: R_GlobalEnv>아무튼 공식이라는 클래스가 따로 있다.
> t[[1]]
`~`
> t[[2]]
y
> t[[3]]
x1 + x2이렇게 직접 뜯어보던가
as.list(k)
[[1]]
`~`
[[2]]
y
[[3]]
x1/x2as.list()로 볼 수 있다. (k에 할당된 공식은 y=x1/x2)
> l="y=x1/x2+x3/x4"
> as.list(l)
[[1]]
[1] "y=x1/x2+x3/x4"참고로 텍스트는 이런 식으로 분리따원 되지 않는다.
> n=as.formula(~x1+sqrt(x2))
> as.list(n)
[[1]]
`~`
[[2]]
x1 + sqrt(x2)y는 생략해도 된다. (실화)
> str(f[[1]])
symbol ~
> str(f[[2]])
symbol y
> str(f[[3]])
language x^2str()을 써서 확인해보면 식 빼고 다 symbol이다. 살려주세요.
as.character()
> as.character(f[[1]])
[1] "~"
> str(as.character(f[[1]]))
chr "~"> as.character(t[[3]])
[1] "+" "x1" "x2"그런데 짜잔 문자열이 되었습니다.
deparse()
> deparse(t[[3]])
[1] "x1 + x2"
> deparse(t)
[1] "y ~ x1 + x2"deparse로도 문자가 되긴 하지만 얘는 식이 부분부분 나눠지지는 않는다. (실화)
'Coding > R' 카테고리의 다른 글
| R 배워보기-5. 데이터 불러오고 쓰기 (0) | 2022.08.20 |
|---|---|
| 번외편-R로 미적분 하기 (0) | 2022.08.20 |
| R 배워보기-3. 문자열 (0) | 2022.08.20 |
| R 배워보기-2. Numbers (0) | 2022.08.20 |
| R 배워보기-1. Basics (0) | 2022.08.20 |
쿡북 분량은 일단 짧다.
다음것도 짧다.
grep()
v=c("피카츄","피츄","라이츄","에몽가","따라큐")
w=c("Alticuno","moltres","zapdos","lugia","Ho-oh")참고로 오늘의 시범조교다.
grep("따라큐",v)
[1] 5grep은 문자를 찾아주는 함수.
grep("alticuno",w)
integer(0)...인데 대소문자를 가린다.
grep("alticuno",w,ignore.case=TRUE)
[1] 1그래서 ignore.case=TRUE를 줘야 대소문자 상관 없이 찾아준다.
^와 $
각각 문자의 시작과 끝을 지정해서 찾아주는 것.
grep("^피",v)
[1] 1 2
# 시작 문자 지정하기
grep("츄$",v)
[1] 1 2 3
# 끝 문자 지정하기시작 문자는 ^(문자), 끝 문자는 (문자)$로 지정하면 된다.
글자수 지정하기
grep("..a",w)
[1] 4grep("..츄",v)
[1] 1 3각각 a와 츄로 끝나는 세글자 이상인 것을 찾으라는 얘기. R은 결과가 벡터 주소로 나온다.
grepl()
grepl("..츄",v)
[1] TRUE FALSE TRUE FALSE FALSE결과를 찾아주긴 하는데 T, F로 반환한다.
gsub()
> text="힘세고 강한 아침"
> gsub("아침","오후",text)
[1] "힘세고 강한 오후"엑셀의 찾아바꾸기 같은 기능. sub()은 처음에 나오는 것 하나만, gsub()은 전부 바꿔준다.
paste()
> a="Thunder"
> b="bolt"
> paste(a,b)
[1] "Thunder bolt"기본적으로는 이렇게 쓴다.
paste(v,w)
[1] "피카츄 Alticuno" "피츄 moltres" "라이츄 zapdos" "에몽가 lugia"
[5] "따라큐 Ho-oh"벡터도 되긴 된다. (각 벡터의 1번끼리 붙이고 2번끼리 붙이고 이런 식)
paste(a,b,sep="")
[1] "Thunderbolt"
paste(a,b,sep=";")
[1] "Thunder;bolt"sep=""으로 구분자 옵션도 줄 수 있다.
paste(v,collapse=",")
[1] "피카츄,피츄,라이츄,에몽가,따라큐"벡터의 원소들은 이런 식으로 collapse를 사용해야 하고
paste(v,w,sep=";",collapse=", ")
[1] "피카츄;Alticuno, 피츄;moltres, 라이츄;zapdos, 에몽가;lugia, 따라큐;Ho-oh"두 개 이상의 벡터를 붙일 때 sep=""을 쓰면 안에 있는 원소들을 저걸로 구별해준다.
paste0()
paste0(a,b)
[1] "Thunderbolt"paste()에서 sep=""인 것과 동일.
sprintf()
파이썬의 format같은 것.
sprintf("%s",text)
[1] "힘세고 강한 아침"
sprintf("%s은 귀엽다",v)
[1] "피카츄은 귀엽다" "피츄은 귀엽다" "라이츄은 귀엽다" "에몽가은 귀엽다"
[5] "따라큐은 귀엽다"따옴표가 없으면 에러난다.
sprintf("%d,",a)
[1] "1," "2," "3," "4," "5,"
> sprintf("%4d,",a)
[1] " 1," " 2," " 3," " 4," " 5,"
# 여기 공백 4개 추가요
> sprintf("%04d,",a)
[1] "0001," "0002," "0003," "0004," "0005,"
# 공백은 너무 여백의 미니까 0을 붙이죠앞에 옵션을 줄 수도 있다. (%d는 int)
> sprintf("%f",pi)
[1] "3.141593"
# 이것은 원주율이다.
> sprintf("%.3f",pi)
[1] "3.142"
# 소수점 아래 세자리만 뽑자.
> sprintf("%1.0f",pi)
[1] "3"
# 아 소수점 필요없어!!!
> sprintf("%2.0f",pi)
[1] " 3"
# 앞에 공백이 생겼다.
> sprintf("%-2.0f",pi)
[1] "3 "
# 뒤에 공백이 생겼다.
> sprintf("%+2.0f",pi)
[1] "+3"
# 앞에 +가 붙었다.
> sprintf("%+20f",pi)
[1] " +3.141593"
> sprintf("%-20f",pi)
[1] "3.141593 "
# +는 앞에 붙는데 -는 또 뒤에 가서 붙는다. 뭘까.%f는 float.
> sprintf("%e",sqrt(2))
[1] "1.414214e+00"
> sprintf("%E",sqrt(2))
[1] "1.414214E+00"%e, %E는 지수형상수.
> sprintf("%g",sqrt(2))
[1] "1.41421"
> sprintf("%g",1e6 * sqrt(2))
[1] "1.41421e+06"
> sprintf("%.g",1e6 * sqrt(2))
[1] "1e+06"
> sprintf("%.G",1e-6 * sqrt(2))
[1] "1E-06"넌 뭐냐?
+%는 %%로 출력한다.
'Coding > R' 카테고리의 다른 글
| R 배워보기-5. 데이터 불러오고 쓰기 (0) | 2022.08.20 |
|---|---|
| 번외편-R로 미적분 하기 (0) | 2022.08.20 |
| R 배워보기-4. 공식 (0) | 2022.08.20 |
| R 배워보기-2. Numbers (0) | 2022.08.20 |
| R 배워보기-1. Basics (0) | 2022.08.20 |
파이썬에서는 똑같은 걸 해보려면 모듈을 불러야 하는데 얘는 모듈 X까! 걍 해! 같은 느낌...
이 다음편 문자열인데 분량 개짧습니다(스포일러)
난수 만들기
runif(1)
[1] 0.7232427runif()를 쓰면 0부터 1까지 중 아무 숫자나 하나 출력한다.
runif(4)
[1] 0.8477728 0.4359127 0.4291748 0.4625472저 괄호 안에 숫자는 범위가 아니고 개수 지정하는거다.
runif(5,min=0,max=100)
[1] 87.75978 48.65714 87.73802 18.87537 75.90590범위는 이런 식으로 지정한다.
floor(runif(6,min=0,max=7))
[1] 1 4 6 4 4 4소수점 떼뿌라!!!
floor는 밑에 설명할건데 그거 보면 왜 저게 6이 아니고 7인지 바로 이해가 된다.
sample(1:6,6,replace=TRUE)
[1] 1 1 2 1 1 5
sample(1:6,6,replace=FALSE)
[1] 6 4 3 2 5 1혹시 Replace가 뭐 하는건지 아시는 분 제보 바람.
오오 인생 그것은 정규분포
에서 나는 저기 어디 한 3시그마쯤 있는거같은데? 아니 곡선 벗어나신 거 같은데요
rnorm(4)
[1] 0.8371672 0.1055429 -0.3464783 -1.2293797정규분포를 따르는 난수를 만들어준다. 처음에 norm 보자마자 노름? 노름공간? 했음...
선형대수학이 이렇게 위험합니다 여러분. 그동네 벡터는 화살표말고 다른게 또 있다. (화살표 있는건 유클리드 벡터)
rnorm(4,mean=50,sd=10)
[1] 48.48528 48.86100 41.74518 52.02730평균이 50, 표준편차가 10인 정규분포를 따르는 난수. 평균이 0이고 표준편차가 1이면 표준정규분포다.
> x=rnorm(400,mean=0,sd=1)
> hist(x)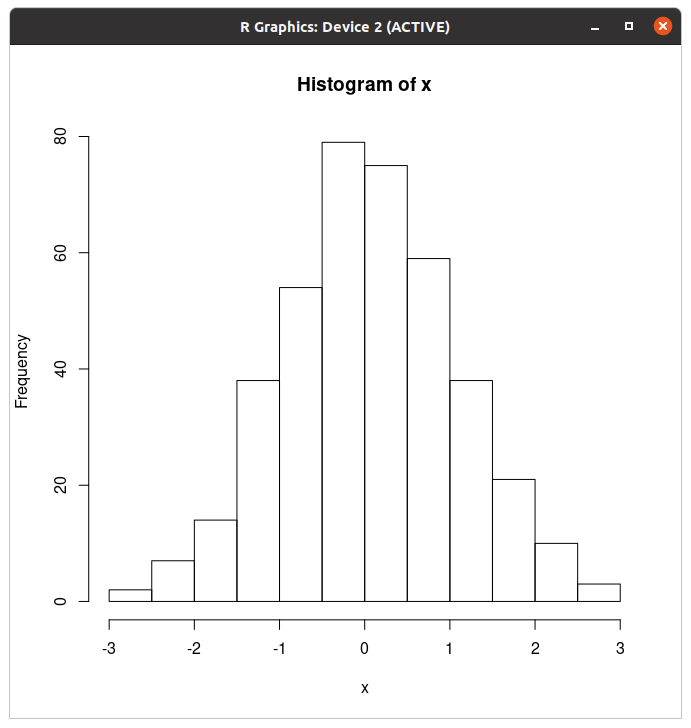
내가 그렇다고 해짜나여!!! (음?)
아 저거 뭐 깔아야되냐고요? ㄴㄴ 걍 했음
시드
> set.seed(1)
> runif(5)
[1] 0.2655087 0.3721239 0.5728534 0.9082078 0.2016819시드를 설정해두면 런이프 5는 계속 저거 뜬다. (저장해둔 시드 날아가면 그대로 안녕...)
> oldseed=.Random.seed
> runif(10)
[1] 0.2059746 0.1765568 0.6870228 0.3841037 0.7698414 0.4976992 0.7176185
[8] 0.9919061 0.3800352 0.7774452
# 만든 시드를 저장하거나
> .Random.seed=oldseed
> runif(10)
[1] 0.2059746 0.1765568 0.6870228 0.3841037 0.7698414 0.4976992 0.7176185
[8] 0.9919061 0.3800352 0.7774452
# 저장한 시드를 불러오거나.Random.seed는 시드를 생성해야 생기는데, 이걸 변수에 저장할 수 있다.
> oldseed=NULL
> runif(10)
[1] 0.93470523 0.21214252 0.65167377 0.12555510 0.26722067 0.38611409
[7] 0.01339033 0.38238796 0.86969085 0.34034900그리고 그걸 Null로 만들면 새로 난수를 만들 수 있다.
> oldseed=NULL
> if(exists(".Random.seed"))
+ oldseed=.Random.seed
> runif(5)
[1] 0.2059746 0.1765568 0.6870228 0.3841037 0.7698414
# 시드를 공백으로 만들고 새 시드를 지정한 다음 저장한다.
> if(!is.null(oldseed))
+ .Random.seed=oldseed
> runif(5)
[1] 0.2059746 0.1765568 0.6870228 0.3841037 0.7698414
# oldseed, 그러니까 새로 지정한 시드가 저장된 저 변수가 Null이 아니면 저장해 둔 시드를 불러오라는 얘기.와 이걸 if로 돌리네.
참고로 .Random.seed는 지역변수라고 한다.
소수점
거 살다보면 소수점 정도는 올릴 수 있지...
v
[1] 0.4976992 0.7176185 0.9919061 0.3800352 0.7774452일단 시범조교 앞으로.
> round(v)
[1] 0 1 1 0 1Round()
> ceiling(v)
[1] 1 1 1 1 1Ceiling()
floor(v)
[1] 0 0 0 0 0Floor()
> trunc(v)
[1] 0 0 0 0 0Trunc()
순서대로 반올림/올림/버림/0 아래로 버림.
round(v,digits=2)
[1] 0.50 0.72 0.99 0.38 0.78w
[1] 9347052311 2121425213 6516737661 1255550960 2672206687
round(w,digits=-3)
[1] 9347052000 2121425000 6516738000 1255551000 2672207000구렛나룻... 아니고 자릿수 남길 거 지정할 수 있다. 구렛나룻? 음수로 남기면 자릿수가 10 100 1000 이런 식으로 올라간다. 엑셀에서 써봤으면 아실 듯.
round(w/5)*5
[1] 9347052310 2121425215 6516737660 1255550960 2672206685round(w/7)*7
[1] 9347052309 2121425215 6516737661 1255550961 2672206684round(w/.02)*.02
[1] 9347052311 2121425213 6516737661 1255550960 2672206687
round(v/.02)*.02
[1] 0.50 0.72 1.00 0.38 0.78
> round(x/.05)*.05
[1] 1.95 0.05 1.90 4.35 1.70반올림할 자릿수를 n의 배수 형식으로 만들 수도 있다.
'Coding > R' 카테고리의 다른 글
| R 배워보기-5. 데이터 불러오고 쓰기 (0) | 2022.08.20 |
|---|---|
| 번외편-R로 미적분 하기 (0) | 2022.08.20 |
| R 배워보기-4. 공식 (0) | 2022.08.20 |
| R 배워보기-3. 문자열 (0) | 2022.08.20 |
| R 배워보기-1. Basics (0) | 2022.08.20 |
이거 미디움에도 올려야하나 좀 고민인게 일단 쿡북 분량이 생각보다 좀 되고 미디움에는 코드블럭이 없음...
네? 설치요? 구글가서 R 설치하는법 찾아보세요. R studio도 같이 깔아야됨.
Python과의 차이점
1) Python과 달리 R은 인덱스 번호가 1부터 시작이다
2) 음수 인덱싱이 Python과 달리 빼고 출력하라는 의미이다(파이썬은 맨 뒤에꺼 달라는 얘기)
3) Python pandas는 기본적으로 결측값을 빼고 계산하지만 R은 결측값을 넣은 상태에서 계산한다. 물론 둘 다 반대로 설정하는 옵션이 존재.
4) R은 결측값을 서브셋 이용해서 대체할 수는 있지만 dropna()같은 기능은 없는 듯 하다.
Data Indexing
v = c(1,2,4,8,16,32)일단 벡터는 이런 식이다.
v[c(1,2,3)]
[1] 1 2 4어? 뭐야 0부터 아냐? (파이썬은 0부터)
v[c(5,4,3)]
[1] 16 8 4거꾸로도 된다.
> data <- read.table(header=T, text='
+ subject sex size
+ 1 M 7
+ 2 F 6
+ 3 F 9
+ 4 M 11
+ ')이놈이 데이터프레임, 즉 표다. (이쪽이 원조라던가...)
data[1,2]
[1] M
Levels: F M파이썬처럼 행렬로 인덱싱하는 것도 된다. (그냥 파이썬 판다스에서 되는건 다 된다고 보면 된다)
data[1,2]
[1] M
Levels: F M컬럼픽이나
data[,1:2]
subject sex
1 1 M
2 2 F
3 3 F
4 4 M행, 열에 대해 범위 인덱싱도 된다.
data[1:4,2]
[1] M F F M
Levels: F M물론 컬럼'만' 뽑는것도 된다.
data[1:2,c("subject","size")]
subject size
1 1 7
2 2 6판다스도 되겠지... 특정 컬럼 픽을 벡터로 지정해서 그걸로 볼 수 있다.
Boolean Indexing
판다스였나 넘파이였나 아무튼 되는거 봤음.
v = c(1,2,4,8,16,32,64,128)준비물: 벡터 (화살표 그거 아님)
v>10
[1] FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE10보다 큰 것은 뭐가 있는지 보여준다.
v[v>10]
[1] 16 32 64 128마스킹이 번거롭다고요? 이런것도 됩니다.
v[c(F,T,T,T,F,F,T,T)]
[1] 2 4 8 64 128이건 True만 뽑아주는건가...
which(data$sex=="M")
[1] 1 4아, 당연한 얘기지만 데이터프레임에서도 통한다.
which(data$sex=="M")
[1] 1 4which(v>10)
[1] 5 6 7 8Which()로도 쓸 수는 있는 모양...
Negative Indexing
위에도 썼지만 파이썬에서 -1이면 맨 뒤에꺼고 R에서 -1이면 1번 빼고 달라는 얘기다. 헷갈리지 말자.
참고로 데이터프레임에서도 먹힌다.
v=[1,2,4,8,16,32,64,128] # 위랑 같은건데 리스트다
v[-1]
128파이썬에서는 이런 식으로 맨 끝에 있는 걸 출력하고
v[-1]
[1] 2 4 8 16 32 64 128R에서는 첫 번째 원소를 빼고 출력한다.
v[-1:-3]
[]
v[-3:-1]
[32, 64]파이썬에서 음수 슬라이싱하면 뒤에 있는 놈들을 출력하지만
v[-1:-3]
[1] 8 16 32 64 128R은 빼고 출력한다.
v[3:]
[8, 16, 32, 64, 128]똑같이 출력하고 싶으면 이렇게 하자.
length(v)
[1] 8
# 일반적인 길이는 이걸로 출력한다
v[-length(v)]
[1] 1 2 4 8 16 32 64
# 아저씨 잠깐만요 하나 어디갔어요length는 밑에서 또 다룰 예정이니 패스. 근데 저거 왜 하나 빼는거임?
서브셋 내놔! 드리겠습니다! 필요없어!
v
[1] 1 3 5 7 9 11 13 15 17시범조교 앞으로.
서브셋을 만든다는 건 일종의 그 뭐라하나... 부분집합을 만든다는 얘기다.
subset(v,v<5)
[1] 1 35보다 작은 걸로 부분집합(서브셋)을 만든 상태.
t
[1] "레어" "미디움" "웰던" "미디움웰던" "미디움레어"
subset(t,t=="웰던")
[1] "웰던"문자도 된다.
v[v>=3]=9
v
[1] 1 9 9 9 9 9 9 9 9뭐야 이거 왜 바껴요
subset(data,subject>=3)
subject sex size
3 3 F 9
4 4 M 11subset(data,select=c(subject,size))
subject size
1 1 7
2 2 6
3 3 9
4 4 11전에 했던거랑 비슷한 코드지만 이놈들은 서브셋을 행/열단위로 만든 것. 그럼 저거 둘이 조합도 되나요?
subset(data,subject>=3,select=c(size))
size
3 9
4 11네. 됩니다.
subset(data,subject %in% c(2,4))
subject sex size
2 2 F 6
4 4 M 11벡터가 들어가있어도 된다.
subset(data,subject>=1 & sex=="M")
subject sex size
1 1 M 7
4 4 M 11subset(data,size>10 | sex=="F")
subject sex size
2 2 F 6
3 3 F 9
4 4 M 11AND와 OR도 된다. (NOT은 기호를 모름)
subset(data,log2(size)>3)
subject sex size
3 3 F 9
4 4 M 11subset(data,size^2>=100)
subject sex size
4 4 M 11연산 결과를 통해 필터링하는 것도 된다. 위는 size에 로그 2를 씌웠을 때 3이 넘는 것(원래 데리터가 88보다 큰 것), 아래는 size에 제곱했을 때 100보다 큰 것.
벡터도 매크로가 되나요
v=rep(1,50)
v
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[39] 1 1 1 1 1 1 1 1 1 1 1 1rep() 쓰면 다 된다. 저렇게 1만 겁나 채우거나
v=rep(1:5,4)
v
[1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5반복하거나(...)
f=rep(factor(LETTERS[1:5]),5)
f
[1] A B C D E A B C D E A B C D E A B C D E A B C D E
Levels: A B C D E와 이게 되네.
변수 정보 뜯어내기
ls(): 지금까지 만들었던 변수 리스트 출력
ls()
[1] "df" "let" "n" "x"
exists(): 야 이 변수 있냐? (있으면 True)
exists("x")
[1] TRUErm(): 변수 삭제(싹 지울때는 rm(list = ls())로 쓴다)
str(): 변수의 형태를 볼 수 있다. ...뭐야 이거 그러면 문자로 어케바꿈?
str(n)
int [1:4] 1 2 3 4str(df)
'data.frame': 4 obs. of 2 variables:
$ n : int 1 2 3 4
$ let: Factor w/ 4 levels "A","B","C","D": 1 2 3 4위: 벡터/아래: Dataframe
length(): 길이를 표시해준다(python의 len()같은 거)
length(let)
[1] 4
nrow(), ncol(), ndom(): 데이터프레임 전용. 각각 행렬 갯수와 차원을 출력해준다. 데이터프레임에 length() 주면 똑띠 안 떠서 저걸로 써야 한다고.
nrow(df)
[1] 4ncol(df)
[1] 2dim(df)
[1] 4 2
Null, NA, NaN
일단 셋 다 결측값이긴 한데... Null은 그냥 값이 없는 것이다. 있었는데 없었습니다 아니고 그냥 없다. NA와 NaN은 결측값으로 들어가 있는 상태.
> is.null(x)
[1] TRUE
> is.null(y)
[1] FALSE
> is.null(z)
[1] FALSE> is.na(x)
logical(0)
> is.na(y)
[1] TRUE
> is.na(z)
[1] TRUE> is.nan(x)
logical(0)
> is.nan(y)
[1] FALSE
> is.nan(z)
[1] TRUE근데 이건 무슨 저세상 결과냐고... NA와 NAN은 NA냐고 하면 트루뜨는데 NA가 NAN이냐고 하면 폴스떠... (x가 널 y가 NA z가 NAN)
v
[1] 1 2 3 NA NaN벡터가 이렇게 되어 있으면 R은 결측값도 껴서 계산한다. 파이썬 판다스와 반대. (판다스는 저 상황에서 결측값을 빼고 계산한다. 물론 반대 기능을 할 수 있는 옵션도 있다)
> mean(v,na.rm=TRUE)
[1] 2그래서 이렇게 해 줘야 결측값을 빼고 계산한다.
v[!is.na(v)]
[1] 1 2 3위에 썼던 필터링하는 방식으로 결측값이 아닌 걸 볼 수 있지만, dropna()처럼 지워주는 건 없는 듯. !가 NOT이여?
v[is.na(v)]=0
v
[1] 1 2 3 0 0 6 7 8일단 서브셋을 활용하면 바꿀 수는 있다.
'Coding > R' 카테고리의 다른 글
| R 배워보기-5. 데이터 불러오고 쓰기 (0) | 2022.08.20 |
|---|---|
| 번외편-R로 미적분 하기 (0) | 2022.08.20 |
| R 배워보기-4. 공식 (0) | 2022.08.20 |
| R 배워보기-3. 문자열 (0) | 2022.08.20 |
| R 배워보기-2. Numbers (0) | 2022.08.20 |
알고리즘이 문제를 푸는 방법이라고 했는데, 그러면 정렬 알고리즘은 뭘 정렬하기 위한 방법이겠지? 네, 맞습니다. 이것도 여러가지가 있는데 대표적인 것 다섯가지만 일단 알아보자.
코드와 알고리즘 관련 설명은
https://velog.io/@jguuun/%EC%A0%95%EB%A0%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
정렬 알고리즘 종류와 설명(파이썬 예제)
정렬은 데이터를 순차적으로 나열하는 방법으로 정렬 알고리즘 별로 수행 성능이 크게 차이납니다. 버블 정렬, 삽입 정렬, 선택 정렬, 병합 정렬, 퀵 정렬을 설명드립니다.
velog.io
여기서 볼 수 있다.
버블 정렬
a = [80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
def bubble_sort(array):
n = len(array)
for i in range(n):
for j in range(n - i - 1):
if array[j] > array[j + 1]:
array[j], array[j + 1] = array[j + 1], array[j]
print(array)
bubble_sort(a)[58, 80, 66, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 80, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 80, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 80, 71, 100, 39, 89, 67, 25, 9]
[58, 66, 80, 71, 39, 100, 89, 67, 25, 9]
[58, 66, 80, 71, 39, 89, 100, 67, 25, 9]
[58, 66, 80, 71, 39, 89, 67, 100, 25, 9]
[58, 66, 80, 71, 39, 89, 67, 25, 100, 9]
[58, 66, 80, 71, 39, 89, 67, 25, 9, 100]
[58, 66, 80, 71, 39, 89, 67, 25, 9, 100]
[58, 66, 80, 71, 39, 89, 67, 25, 9, 100]
[58, 66, 71, 80, 39, 89, 67, 25, 9, 100]
[58, 66, 71, 39, 80, 89, 67, 25, 9, 100]
[58, 66, 71, 39, 80, 89, 67, 25, 9, 100]
[58, 66, 71, 39, 80, 67, 89, 25, 9, 100]
[58, 66, 71, 39, 80, 67, 25, 89, 9, 100]
[58, 66, 71, 39, 80, 67, 25, 9, 89, 100]
[58, 66, 71, 39, 80, 67, 25, 9, 89, 100]
[58, 66, 71, 39, 80, 67, 25, 9, 89, 100]
[58, 66, 39, 71, 80, 67, 25, 9, 89, 100]
[58, 66, 39, 71, 80, 67, 25, 9, 89, 100]
[58, 66, 39, 71, 67, 80, 25, 9, 89, 100]
[58, 66, 39, 71, 67, 25, 80, 9, 89, 100]
[58, 66, 39, 71, 67, 25, 9, 80, 89, 100]
[58, 66, 39, 71, 67, 25, 9, 80, 89, 100]
[58, 39, 66, 71, 67, 25, 9, 80, 89, 100]
[58, 39, 66, 71, 67, 25, 9, 80, 89, 100]
[58, 39, 66, 67, 71, 25, 9, 80, 89, 100]
[58, 39, 66, 67, 25, 71, 9, 80, 89, 100]
[58, 39, 66, 67, 25, 9, 71, 80, 89, 100]
[39, 58, 66, 67, 25, 9, 71, 80, 89, 100]
[39, 58, 66, 67, 25, 9, 71, 80, 89, 100]
[39, 58, 66, 67, 25, 9, 71, 80, 89, 100]
[39, 58, 66, 25, 67, 9, 71, 80, 89, 100]
[39, 58, 66, 25, 9, 67, 71, 80, 89, 100]
[39, 58, 66, 25, 9, 67, 71, 80, 89, 100]
[39, 58, 66, 25, 9, 67, 71, 80, 89, 100]
[39, 58, 25, 66, 9, 67, 71, 80, 89, 100]
[39, 58, 25, 9, 66, 67, 71, 80, 89, 100]
[39, 58, 25, 9, 66, 67, 71, 80, 89, 100]
[39, 25, 58, 9, 66, 67, 71, 80, 89, 100]
[39, 25, 9, 58, 66, 67, 71, 80, 89, 100]
[25, 39, 9, 58, 66, 67, 71, 80, 89, 100]
[25, 9, 39, 58, 66, 67, 71, 80, 89, 100]
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]인접한 두 수를 비교해가면서 정렬하는 방식. 비유하자면 얘가 얘보다 출석번호가 큰가를 일일이 확인하고 출석번호가 더 크면 뒤로 보낸다.
보시다시피 코드는 심플하지만, 실행 결과를 보면 하나하나 대조해가면서 얘가 얘보다 크면 뒤로 빼는 방식이라 효율면에서는 씁 에반데 소리가 절로 나온다.
선택 정렬
a = [80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
def selection_sort(array):
n = len(array)
for i in range(n):
min_index = i
for j in range(i + 1, n):
if array[j] < array[min_index]:
min_index = j
array[i], array[min_index] = array[min_index], array[i]
print(array)
selection_sort(a)[9, 58, 66, 100, 71, 39, 89, 67, 25, 80]
[9, 25, 66, 100, 71, 39, 89, 67, 58, 80]
[9, 25, 39, 100, 71, 66, 89, 67, 58, 80]
[9, 25, 39, 58, 71, 66, 89, 67, 100, 80]
[9, 25, 39, 58, 66, 71, 89, 67, 100, 80]
[9, 25, 39, 58, 66, 67, 89, 71, 100, 80]
[9, 25, 39, 58, 66, 67, 71, 89, 100, 80]
[9, 25, 39, 58, 66, 67, 71, 80, 100, 89]
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]배열을 쓱 보면서 가장 작은 값을 앞으로 보낸다. 앞에서부터 뒤로 쭉 둘러보면서 1번을 맨앞으로, 그 다음 2번을 맨 앞으로, 3번을 맨 앞으로... 이런 식으로 진행한다. 버블 정렬에 비해 과정이 짧아보이는데 기분탓...은 아님.
삽입 정렬
a = [80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
def insert_sort(array):
n = len(array)
for i in range(n):
min_index = i
for j in range(i, 0, -1):
if array[j - 1] > array[j]:
array[j - 1], array[j] = array[j], array[j - 1]
print(array)
insert_sort(a)[80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
[58, 80, 66, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 80, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 80, 100, 71, 39, 89, 67, 25, 9]
[58, 66, 71, 80, 100, 39, 89, 67, 25, 9]
[39, 58, 66, 71, 80, 100, 89, 67, 25, 9]
[39, 58, 66, 71, 80, 89, 100, 67, 25, 9]
[39, 58, 66, 67, 71, 80, 89, 100, 25, 9]
[25, 39, 58, 66, 67, 71, 80, 89, 100, 9]
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]데이터의 사이를 비우고 그 사이로 순서에 맞는 데이터를 넣는 정렬 구조. 출석번호 2번과 4번의 사이를 벌리고 그 사이로 3번을 넣는다. 보통 사람들이 책이나 서류철같은 거 정리할 때 이런 식으로 한다.
병합 정렬
a = [80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
def merge_sort(array):
if len(array) < 2:
return array
mid = len(array) // 2
low_arr = merge_sort(array[:mid])
high_arr = merge_sort(array[mid:])
# 일단 짼다
merged_arr = []
l = h = 0
while l < len(low_arr) and h < len(high_arr):
if low_arr[l] < high_arr[h]:
merged_arr.append(low_arr[l])
l += 1
else:
merged_arr.append(high_arr[h])
h += 1
merged_arr += low_arr[l:]
merged_arr += high_arr[h:]
print(merged_arr)
return merged_arr
# 그리고 비교한다
merge_sort(a)[58, 80]
[71, 100]
[66, 71, 100]
[58, 66, 71, 80, 100]
[39, 89]
[9, 25]
[9, 25, 67]
[9, 25, 39, 67, 89]
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]폰 노이만이 고안한 알고리즘.
이 양반에 대한 이야기는 여기를 참고하시고... (야공만 재밌음)
https://www.facebook.com/engineertoon/posts/579547758898750
Facebook에 로그인
Notice 계속하려면 로그인해주세요.
www.facebook.com
이게 그래서 뭐냐면... 배열의 길이가 0이나 1이 될 때까지 쪼개고 비교해서 합한다. 그러니까
[80, 58, 66, 100, 71, 39, 89, 67, 25, 9]1) 이 배열을 [80, 58, 66, 100, 71] [39, 89, 67, 25, 9]로 나누고
2) 또 배열을 [80, 58] [66, 100, 71] [39, 89] [67, 25, 9]로 나누고
3) 계속 나눠서 배열의 길이가 1이 될 때까지 나눈다. (홀수 배열은 아마도 [1] [2, 3] 이런 식인 듯)
4) 나눈 배열에 있는 숫자를 비교해서 작은 쪽을 앞으로 빼고 다시 합친다. (if문이 그래서 있음)
대충 이렇게 된다.
퀵 정렬
a = [80, 58, 66, 100, 71, 39, 89, 67, 25, 9]
def quick_sort(array):
if len(array) <= 1:
return array
pivot = len(array) // 2
front_arr, pivot_arr, back_arr = [], [], []
for value in array:
if value < array[pivot]:
front_arr.append(value)
elif value > array[pivot]:
back_arr.append(value)
else:
pivot_arr.append(value)
print(front_arr, pivot_arr, back_arr)
return quick_sort(front_arr) + quick_sort(pivot_arr) + quick_sort(back_arr)
quick_sort(a)[25, 9] [39] [80, 58, 66, 100, 71, 89, 67]
[] [9] [25]
[80, 58, 66, 71, 89, 67] [100] []
[58, 66, 67] [71] [80, 89]
[58] [66] [67]
[80] [89] []
[9, 25, 39, 58, 66, 67, 71, 80, 89, 100]로직 잘못 짜면 성능을 조지긴 한데 아무튼... 한 반에 25명이 있고 출석번호 순으로 줄을 세울 때 퀵 알고리즘은 기준점을 두고 그걸 중심으로 분할한다. 이 코드에서는 배열의 가운데(여기서는 길이가 10인 배열의 5번 값)를 기준으로 해서 정렬했다. 이것도 일종의 분할 알고리즘이라 피벗을 중심으로 앞을 정렬하고 뒤도 기준점을 잡아서 정렬한 것을 볼 수 있다.
각 알고리즘의 소요시간 비교하기
버블 알고리즘이 개똥이라는데 진짜일까? 확인해보자. 일단 확인하기 위한 배열이 하나 필요한데, 시간복잡도가 체감되는 건 '데이터가 많아질때'이다. 그래서 배열의 길이를 10개 뭐 이렇게 스몰스케일로 안 하고
[793, 27, 646, 705, 964, 814, 804, 300, 942, 614, 765, 790, 739, 191, 474, 503, 887, 908, 476, 733, 964, 564, 579, 22, 395, 645, 713, 763, 830, 909, 206, 197, 540, 489, 124, 696, 957, 882, 759, 557, 198, 987, 424, 777, 111, 893, 813, 329, 570, 707, 226, 423, 246, 86, 878, 192, 421, 559, 871, 62, 136, 768, 831, 813, 477, 714, 805, 279, 186, 281, 404, 252, 548, 546, 594, 1, 627, 351, 721, 11, 637, 386, 657, 907, 35, 753, 827, 227, 116, 745, 586, 105, 4, 444, 488, 599, 404, 3, 291, 634, 848, 500, 260, 273, 575, 549, 713, 166, 109, 930, 761, 997, 21, 333, 160, 569, 927, 210, 315, 592, 330, 305, 839, 931, 822, 957, 738, 552, 478, 886, 809, 855, 579, 965, 661, 572, 219, 878, 830, 542, 82, 401, 30, 276, 664, 596, 616, 500, 74, 382, 191, 947, 521, 715, 575, 65, 110, 722, 751, 710, 953, 229, 586, 852, 447, 604, 529, 82, 760, 755, 167, 609, 152, 229, 276, 834, 84, 411, 817, 988, 572, 318, 192, 292, 438, 708, 450, 404, 204, 348, 387, 401, 88, 431, 246, 131, 55, 816, 211, 726]길이 200짜리 배열을 준비했다. (물론 난수로 만들었음) 그리고 하나 더 있는데... 코드가 구동되는 시간을 뭐 스톱워치로 잴 수는 없잖음?
import random, sys, time
start = time.time()
N = int(sys.stdin.readline())
def random_array(n):
a = []
for i in range(n):
i = random.randrange(1,101)
a.append(i)
for j in a:
if i == j:
i = random.randrange(1,101)
else:
continue
return a
print(random_array(N))
print('소요시간: ',round(time.time() - start,3))import time 하고 시작시간 지정하고 완료 후의 시간에서 빼서 소요시간을 계산할 수 있다.
해당 코드로 돌렸을 때 다섯가지 알고리즘의 소요시간은
1) 버블 정렬 소요시간: 7.392
2) 선택 정렬 소요시간: 0.075
3) 삽입 정렬 소요시간: 0.08
4) 병합 정렬 소요시간: 0.003
5) 퀵 정렬 소요시간: 0.000118 (3자리 했더니 안나와서 자리수 늘렸음)
버블 정렬이 진짜 느리다. 그래서 진짜 막 이거 아님 안될것같다... 그런거 아니면 버블 정렬은 지양하는 게 좋다고. 버블 정렬이 압도적이라 그렇지 2, 3번이 전체적으로 그렇게 효율이 좋지 않은데... 왜 그럴까? 병합이랑 퀵은 왜 그렇게 빠를까? 병합 정렬과 퀵 정렬은 배열을 '분할'해서 정렬한다. 출석 번호 정렬로 치자면 위에 3개는 한 반 전체를 정렬하는거고, 아래 두 개는 어떤 기준으로 한 반의 학생들을 그룹으로 나눠서 정렬한다.
꼭 이렇게까지 해야 하나요?
근데 이걸 왜 정렬까지 해야 하나요? 그것은 간단하다. 데이터를 어떤 기준으로든 정렬해두면, 이진 탐색 알고리즘을 이용할 수 있다. 예? 그게 뭔 소리유? 예를 들어보자.
평소처럼 실험을 하던 제육쌈밥군(R로 스탠다드 커브 그리기 참고). 그러던 어느 날, 교수님께 퀘스트가 들어왔다.
"여기 있는 실험노트 중, 2015년 이전에 작성된 노트를 내 방으로 옮겨줘. "
제육쌈밥군이 있는 실험실은 교수님의 인기가 좋아 대학원을 거쳐 간 사람들이 꽤 있었고, 노트는 어림잡아 3~400권 정도는 되는 것 같았다.
정렬이 없을 때: 일단 제육쌈밥군은 최근에 실험실에 들어온 선배들의 노트를 제외하고, 책꽂이에 꽂혀 있는 실험노트를 전부 꺼냈다. 그리고 실험노트 앞쪽에 적힌 날짜를 보면서 일일이 연도를 확인하면서 2015년 이전에 작성된 노트를 골라냈고, 교수님 사무실로 옮겼다.
정렬이 있을 때(전체 정렬): 제육쌈밥군은 노트 뭉치를 가져와서 한데 모은 다음, 표지에 쓰인 연도순으로 정렬했다. 한참동안 노트를 정리한 제육쌈밥은 2015년 이전에 작성된 노트를 교수님 사무실로 옮겼다.
정렬이 있을 때(분할 정렬): 제육쌈밥군은 노트 뭉치를 가져와서 책꽂이 칸별로 쌓았다. 그리고 노트 더미에서 노트를 꺼내 앞표지를 확인하면서 노트를 정리한 제육쌈밥은 정리를 마치고 2015년 이전에 작성된 노트를 교수님 사무실로 옮겼다.
세 가지 케이스를 얼핏 들어서는 별로 차이가 없을 것 같지만, 노트를 일단 정렬하게 되면 2014년 12월에 작성된 마지막 노트에 표시하고 그것만 잘라서 정리하면 된다. 정리하는데 시간은 들겠지만, 정리하고 나서 그냥 기준에 따라 뚝 자르면 되는 것.
'Coding > 코딩잡담' 카테고리의 다른 글
| 시스템 소프트웨어와 응용 소프트웨어 (0) | 2022.08.31 |
|---|---|
| 익명함수 김람다씨 (0) | 2022.08.29 |
| :root와 var의 조합은 정말 개편합니다. (0) | 2022.08.26 |
| 쿼리와 SQL (0) | 2022.08.20 |
| 지금까지 썼던 IDE&에디터 풀어봄 (0) | 2022.08.20 |
본인쟝... 이래뵈도 몽고DB 이전에 액세스(odbc)와 MySQL(jdbc)를 썼었다. 근데 데이터베이스를 쓰다보면 쿼리 어쩌고 하는데, 쿼리가 뭔지 모르겠는겨. 그렇게 걍 쓰다가 전전직장에서 친해진 개발자님에게 쿼리가 뭔지 물어봤다.
본인: 쿼리가 뭐예요?
개발자님: 데이터베이스에 접근해서 뭐 해달라고 요청하는거요.
진짜 이게 쿼리임.
근데 데이터베이스가 뭔데 거기에 접근해서 뭘 해달라고 하는것인가... 데이터베이스는 '데이터'의 집합체라고 보면 된다. 그리고 데이터는 우리가 생각하는 그 데이터가 맞다. 핸드폰 요금제 말고... 예? 그 데이터 생각하셨다고요? 아 그럼 일단 데이터에 대해 설명을 좀 하고 가겠음.
데이터?
데이터는 문자, 그림, 소리 등으로 이루어져 있는데 크게 질적 데이터와 양적 데이터로 나눈다. 퀄리티와 콴티티인데 둘이 그럼 무슨 차이예요? 양적 데이터는 나이, 키, 몸무게, 온도, IQ 등 숫자로 나타낼 수 있는 것이고, 질적 데이터는 혈액형과 학점처럼 숫자로 표현이 불가능한 것이다. 물론 그렇다고 해서 '숫자로 표현할 수 있으면 무조건 양적 데이터'인 건 아니다. 왜, 가끔 설문조사를 하다 보면 나이가 아니라 나이대를 선택하는 옵션이 있을 것이다. 10~19세, 20~29세 이런 식으로. 이건 수치형 자료인 나이를 질적 데이터 중 하나인 범주형 자료로 만든 것이다.
각 데이터 형태에는 또 세부 카테고리가 있는데 질적 데이터는 순위형과 명목형으로 나눈다. 이 둘은 자료를 분류하는 데 있어서 '순서에 의미가 있는가?'를 보는 것이다. 혈액형은 A, B, O, AB 네 개로 나누지만 딱히 이 네 개의 순서에 의미는 없으므로 명목형이고, 학점은 A, B, C, D, F라는 순서에 의미가 있으므로 순위형이다. (학바학인데 0, +만 있는 데도 있고 -, 0, +로 나누는데도 있다. 본인은 전자) 명목형의 또 다른 예시는 Baltimore classification으로, 바이러스를 게놈이 뭐냐(DNA, RNA), 게놈 방향(+, -)이 뭐냐, mRNA 복제 방식이 뭐냐에 따라 나눈 것. 아, 분류를 한 사람 이름이 당연하게도 볼티모어다. 서던블롯도 서던이 만든거다 어떻게 사람 이름이 남쪽 ㅋㅋㅋㅋ
양적 데이터는 연속형 자료와 이산형 자료로 나뉘는데, 둘의 차이는 '셀 수 있는가?'이다. 뭔 A cup of coffee같은 소리인지는 나도 모름. 아무튼, 연속형 자료는 자료가 연속되는거라서 셀 수 없다. 시간이 대표적인 예시. 어? 우리 몇시 몇분 이런거 얘기하잖아요. 아 그건 엄밀히 말하자면 시'각'이다. 순간은 셀 수 있지만, 흐름은 셀 수 없거든...
데이터베이스의 예
데이터베이스가 데이터의 집합체라고 했는데, 예를 들어보자.

ChEMBL이라는 데이터베이스에 있는 아스피린의 정보 중 일부다. 이 분자의 이름이 뭐고(이름도 관용명 계통명 있다), 켐블 아이디가 뭐고(Key값같은 거), 화학식이 뭐고, 진행 단계(약물 허가 단계가 어디인지를 말한다. 쟤는 시판중)는 어디고, 분자량은 뭐고, 동의어는 뭐고, 어떤 이름으로 팔리고(아세트아미노펜도 팔리는 약 이름 중 하나가 타이레놀인 것이다), 무슨 분자이고 이런 게 데이터베이스에 담겨있다. 저기서 분자량만 수치형 데이터. 켐블은 저런 약물들의 데이터베이스이기때문에 현존하는 약물 분자에 대해 저런게 다 있다. (물론 일부 없는것도 있기는 함)
좀 간단한 예를 들어보자. 요즘은 동네 맛집이라고 해서 내가 사는 동네(혹은 대학가) 맛집에 대한 정보가 있는 사이트나 앱이 있다. 세종대 근처 맛집에 대한 정보로 뭐가 필요할까? 일단 식당의 기본 정보로는 맛집의 위치와 전화번호, 휴일 정보, 여닫는 시간 및 Break time에 대한 정보(브레이크 타임에는 장사를 잠깐 쉬고 다음 장사를 준비한다고 보면 된다), 업종(크게는 식당 or 카페, 세분류로 들어가면 한식 일식 중식 양식 이렇게 있다)이 필요할 것이다. 그리고 해당 식당에 대한 평가 데이터로는 평가한 사람과 별점, 평가 내용이 들어간다. 이런 데이터들을 차곡차곡 쌓아가는 게 데이터베이스.
그럼 엑셀을 쓰면 되지 않느냐... 할 수 있다. 엑셀도 작은 스케일의 DB를 관리할 때는 좋다. 좋은데... 이게 스케일이 좀 커지면 열다가 뻗고 수정하다가 뻗고 읽다가 뻗어서 작업자 혈압 수직상승한다. 그리고 엑셀파일은 동시에 열 수가 없다. 각각 엑셀파일을 받아서 열고 수정하는 건 할 수 있지만, 공유 폴더에 있는 엑셀파일을 동시에 열고 수정할 수가 없다. 세번째 직장에서 주간일지를 엑셀파일로 관리하는데, 금요일에 이거 쓸 때 되면 이것땜에 순서 정해서 쓰고 그랬다.
쿼리를 어떻게 할까?
그럼 위에서 '쿼리는 데이터베이스에 접근해서 뭐 해달라고 요청하는거'라고 했는데, 뭘 요청함? 위에 있는 세종대 근처 맛집 DB를 예시로 들어보자. 맛집의 기본 정보가
1) 위치
2) 전화번호
3) 브레이크타임 및 여닫는 시간
4) 휴일 정보
5) 업종
이렇게 있다고 했는데, 앱은 이 데이터를 가져올 때 데이터베이스에 접근해서 가져오게 된다.
사례 1: 1시 반 강의가 끝나고 4시 반에 수업이 있는 김양상추씨. 공강시간에 도서관에 가자니 거기서 3시간동안 있기엔 또 졸려서 잘 것 같고... 끼니도 간단하게 빵으로 때울 겸 해서 친구들과 근처 카페를 가기로 했다.
사례 2: 오늘따라 중식이 당기는 김부추씨. 하지만 세종대 근처 맛집은 처음이었던 신입생 김부추씨는 근처 맛집 중에서 별점이 가장 높은 중식당을 한번 가보기로 했다.
사례 3: 대학원에 다니고 있는 박숟갈(Spoon Park)씨. 오늘은 교수님께서 박숟갈씨 논문도 나온 기념으로 고깃집에서 회식을 하기로 했다. 실험 끝내고 얼른 가서 먹을 수 있게 세종대 후문쪽으로 알아보라는 교수님 말씀에 후배인 김메탕씨와 함께 맛집을 알아보게 되었다.
위 세 가지 사례를 예로 들어보자.
사례 1의 경우 업종이 카페인 세종대 근처 맛집을 찾아야 하니까, 데이터베이스에서 '업종이 카페인 맛집'을 찾을 것이다. 그리고 추가적으로 브레이크타임에 대한 정보가 필요하다면 '업종이 카페이면서 브레이크타임이 없는 맛집'을 찾게 된다. 이 때 앱을 통해 데이터베이스에 접근해서 업종 = 카페인 맛집을 보여달라고 쿼리를 때리게 된다. 비슷하게 사례 2는 업종 = 중식 인 맛집을 별점이 높은 순으로 정렬해서 보여달라는 쿼리를 때리게 되고, 사례 3은 업종 = 고깃집인 식당을 찾은 다음 지도를 통해 위치를 체크하면 된다(요즘 맛집앱은 지도에 띄워준다).
참고로 나때는 중식 당기면 만강홍... 운을 시험하고 싶다면 만강짜장이었다. 만강짜장이 복불복의 상징이 된 이유는, 이건 기본적으로 매운데 매운 정도가 그 날 조리하시는 분 컨디션에 따라 다르기 때문... 현재는 이전하면서 세종원으로 이름을 바꿨다.
SQL
Structured Query Language의 약어. RDBMS(관계형 데이터베이스)에서는 얘가 국룰이다. 데이터베이스에서 데이터를 조회/입력/수정/삭제/저장하기 위해 필요한 질의언어. 즉, RDBMS에서 CRUD를 진행하기 위한 질의언어이다. 실제로도 써보면 그렇게 어려운건 없... 아냐 어려워... 빡세...
SQL 구문은 크게 데이터 정의, 조작, 제어로 나뉜다. '
데이터 정의
수정이나 삭제... CRUD는 맞는데, 이건 데이터베이스단위로 들어간다. 즉 테이블이나 데이터베이스를 만들고, 이를 수정하고, 삭제하고, 초기화(TRUNCATE)한다. 삭제가 왜 딜리트가 아니냐면 딜리트는 밑에 따로 나옴. 근데 Read가 없…
-CREATE
-ALTER
-DROP
-TRUNCATE
데이터 조작
위에껀 데이터베이스 자체를 만들고 없애고 하는거고, 얘는 데이터베이스 안에 있는 '데이터'에 대한 CRUD이다. 위에 있는 맛집 앱을 예로 들자면, 데이터 정의는 맛집에 대한 데이터베이스 자체에 적용하는거고, 얘는 맛집 데이터베이스 안에 있는 맛집 데이터에 적용하는 것. 즉, 맛집의 생성/수정(정보 수정)/삭제가 이쪽이다.
-INSERT (CRUD의 C)
-SELECT (MySQL의 SELECT * from table 할 때 그거, CRUD의 R)
-UPDATE (CRUD의 U)
-DELETE (CRUD의 D)
데이터 제어
위에놈은 모디피케이션 아니고 매니플레이션인데 얘는 왜 컨트롤이여 위에 두 개는 데이터베이스와 데이터에 대한 CRUD이고, 얘는 접근 권한(리눅스로 치자면 rwx)같은 걸 한다. 네개 중 위 두 개는 접근 권한, 아래 두 개는 트랜잭션(쪼갤 수 없는 업무 처리의 최소 단위) 관련.
-GRANT
-REVOKE
-COMMIT
-REROLL
GRANT와 REVOKE가 서로 반대 개념인데, GRANT는 특정 사용자에게 데이터베이스에 접근해서 뭔가를 할 권한을 주는거고 REVOKE는 반대로 권한을 뺏는다. COMMIT은 RREROLL과 서로 번대되는 개념으로, COMMIT은 트랜잭션을 저장하고 현재 트랜잭션을 종료하는 것이고, REROLL은 반대로 현재 트랜잭션에 작업했던 내용을 전부 취소하고 되돌리는 것.
COMMIT과 REROLL이 이해가 잘 안 된다면, COMMIT은 깃헙의 커밋을 생각하면 된다. 깃헙에 뭘 올릴때는 풀로 가져오고(변경사항 이런거), 커밋으로 OK하고(코멘트 추가요), 푸시로 밀어서 그걸 반영해야 올라간다. 그니까 깃헙에 올릴때는 풀-커밋-푸시 삼단콤보가 중요하다. REROLL은 롤백이라고 보면 된다. 작업하다 뭐가 뻑났어 그러면 ctrl+z 하는것처럼.
'Coding > 코딩잡담' 카테고리의 다른 글
| 시스템 소프트웨어와 응용 소프트웨어 (0) | 2022.08.31 |
|---|---|
| 익명함수 김람다씨 (0) | 2022.08.29 |
| :root와 var의 조합은 정말 개편합니다. (0) | 2022.08.26 |
| 정렬 알고리즘 (0) | 2022.08.20 |
| 지금까지 썼던 IDE&에디터 풀어봄 (0) | 2022.08.20 |
참고로 따로 분류는 하지 않지만 원래 IDE가 아닌데 코딩용으로 쓰는 게 있습니다. 예를 들자면 VScode.
ATOM
텍스트 에디터고 보통은 윈도나 리눅스나 괴담수사대 집필용으로 쓰고 있음. 가끔 py파일 수정할 때 쓰기도 하고... 본인 막코딩 잘 안합니다.
VScode
얘도 텍스트 에디터임. (충격) 일단 얘는 웹버전이 있는데 웹버전에서는 코드 실행은 안되고 작성이 돼서 윈도에서는 웹버전 VScode에서 작성하고 web ide로 돌려보는 식으로 쓰고 있음.
실행하는 법도 개편한데 리눅스 기준으로 터미널에서 code 부르던가 시작메뉴 비슷한 거기 아이콘이 있어서 걍 그거 누르면 됩니다. 진짜 실행이 이렇게 개친절할 수가 없어요. 심지어 실행도 빨리 돼.
근데 요즘 노트북 문제인건지 코드 치다가 커서 다중으로 뜨고 키보드 먹통되더라... 재부팅하면 되긴 한데 재부팅 말고 해결책이 없음.
PyCharm
젯브레인에서 만든 IDE. 당연한 얘기지만 input과 sys.stdin.readline()이 다 먹힘. (이건 VScode도 둘 다 먹힘) 둘 다 안먹는것도 있는데 이정도면 장점 쌉가능이죠. 대신 VScode는 Biopython 모듈을 못 불러오는데 얘는 그것도 불러올 수 있어서 Biopython 모듈이 필요한 경우 Jupyter나 얘 통해서 하고 있음.
윈도우에서는 얘 안써봐서 모르겠는데 일단 리눅스에서 써 본 결과 단점이 두 개가 있음. 일단 첫번째로 구동하는데 되게 오래걸림. 얘 쓰다가 VScode 쓰면 VScode가 우사인볼트같음.
두번째로, 얘는 소환하기가 개복잡하고, 설치 후 설정이 따로 있음. 일단 다른 IDE나 텍스트 에디터는 홈페이지 가서 깔든(보통 dpkg -i나 tar -xvzf, IDE 바이 IDE지만 리눅스 공용으로 나오는 게 있고 계열 따라서 나뉘는 게 있음) apt 어쩌고 해서 깔든 wget으로 깔든 '설치를' 해야되는데 파이참은 그게 아니라 압축 파일을 가져와서 그걸 폴더에 압축해제 하면 끝임. 그래서 바로가기 아이콘도 따로 설정해줘야 하고, 별도로 설정하지 않으면(물론 본인은 귀찮아서 안함) 터미널 통해서 압축 해제한 폴더로 가서 sh pycharm.sh를 입력해야 실행이 됨. 그나마 터미널에서 탭키 누르면 자동완성은 되니 다행이지...
업데이트도 그냥 아 때 됐나 하면 파이참 홈페이지 가서 새거 받아서 압축 풀면 땡임.
Spyder
전 직장 개발자님의 추천으로 설치한 IDE인데 일단 설치 잘못해서 한글 입력이 안 되는 거 빼면 정말 좋음. 소환도 터미널에서 spyder 누으면 끝이고, pycharm보다 실행도 빠름.
소환은 터미널단에서 spyder 치면 끝. 한글 입력이 안 되는 이유는 리눅스에서 파이썬 관련된 걸 설치할 때 pip install ~로 설치하는거랑 아나콘다를 깔고 conda install ~ 하는 게 있는데, 얘가 후자고 후자대로 안 하면 입력 삐꾸나서 저렇게 됨. 여러분은 아나콘다 깔고 conda install ~로 하시길...
https://github.com/spyder-ide/spyder/issues/16862
How can I off right alt? · Issue #16862 · spyder-ide/spyder
Issue Report Checklist [V] Searched the issues page for similar reports [V] Read the relevant sections of the Spyder Troubleshooting Guide and followed its advice Reproduced the issue after updatin...
github.com
여기서도 개발자님이 한/중/일어 쓰려면 아나콘다 경유하라고 하심. (출처: 본인 질문글)
아, 얘는 왜 그런지 모르겠는데 sys,stdin.readline() 치면 형변환 에러 뜸.
Jupyter
...얘 IDE 맞음? 근데 에디터도 아님
예전에 사업계획서에서 Jupyter notebook을 봤는데 그때는 걍 놋북인가... 했음. 근데 이게 인공지능 교육에서 나와요! 찾아보니까 laptop이 아니었어... 아니 인공지능이 노트북이 왜 필요해 서버가 있는데
Jupyter notebook이랑 Jupyter lab이 있는데 본인은 전자가 익숙해서 전자 씀. 설치 실행 정말 개 간단하고 실행하면 브라우저에서 코딩이 가능함.
얘는 쓰면서 다른 IDE나 텍스트 에디터랑 다른 특징이 두 개가 있는데, 첫번째로 블록이라는 개념이 있음. 이친구는 인터프리터라 실행해야 하는 코드를 블록 안에 묶어놓고 그 블록만 실행하면서 테스트가 가능함. 예를 들어서
import 김모듈
import 이모듈
from 박모듈 import 박기능
# 모듈
변수 1
변수 2
# 변수
코드 1
코드 2
출력이런 식으로 코드가 있으면 VScode나 파이참, 스파이더의 경우 저걸 처음부터 끝까지 다 돌려야 함. 코드 1의 로직을 수정해서 테스트를 할래도 모듈 데려오고 변수 정하는 거기서부터 해야되는데 Jupyter는 블록을 모듈/변수/코드1/코드2 이런 식으로 나눠놓고 코드1이 있는 블록만 돌려가면서 테스트가 가능함.
그리고 다른 하나는, 보통 파이썬 파일은 py파일인데 얘는 ipynb파일로 저장된다. VScode에서 얘를 읽기도 하고 왜, 이걸 py파일로 변환할 수도 있다. GitHub에서도 두 파일의 표시 형식이 다른데, py파일은 줄글로 보이고 ipynb는 블록블록으로 보인다.
일단 첫 번째 특징때문에 복잡한 거 코딩할 때 이용하는 편이고 프로젝트 제한효소나 프로젝트 워드클라우드도 이걸로 한 다음 py파일로 옮긴 것. 대신 얘는 sys.stdin.readline()이 안된다. (입력을 아예 안받음)
근데 Python은 파이썬인데 얘는 왜 주피터임?
Eclipse
자바 계열 코딩할 때 좋은 IDE. Python도 지원은 하는데 걍 파이참이나 VScode 쓰는 게 좋다. 전자정부프레임워크도 얘 끼고 들어간다.
설치 및 셋업이 정말 개 복잡하다. 자바가 설치되어 있어야 설치가 가능한데다가 자바 설치하고 환경변수도 잡아야 하고, 얘 기본 글꼴은 한글이 이상하게 나와서 한글 글꼴(보통 D2coding)로 바꿔줘야 한다. 자바는 아마 jdk jre 둘 다 필요한듯. 일단 난 둘 다 깔았음.
인텔리제이 좋다던데 난 안써봐서 모르겠음. 근데 한가지 확실한 건 얘 개무겁다... 게이밍 노트북 아니면 실행하다 사리 나오게 무겁다. 어느 정도냐면 고대에서 일할 때 팀장님이 이클립스 돌아가는 거 보시더니 진지하게 컴퓨터 바꿔야겠다고 하셨음.
기타 IDE 및 에디터
R studio: R과 얘는 거의 붕어빵과 앙금같은 관계지만, 일단 난 리눅스에서 R 할 일 있으면 터미널에서 R 부른다. 그래서 안씀.
MySQL Workbench: 얘는 IDE가 아니고, 원래 MySQL을 CUI에서 해야되는데 그걸 GUI에서 돌릴 수 있는 거다. 일단 있으면 편하긴 함.
메모장: 그냥 ATOM 쓸게요.
Bracket: Adobe(포토샵 만든 거기 맞음)에서 만든거라는데 왜 종료요... ATOM보단 가볍다. (ATOM도 실행하는데 생각보다 시간 좀 걸림)
'Coding > 코딩잡담' 카테고리의 다른 글
| 시스템 소프트웨어와 응용 소프트웨어 (0) | 2022.08.31 |
|---|---|
| 익명함수 김람다씨 (0) | 2022.08.29 |
| :root와 var의 조합은 정말 개편합니다. (0) | 2022.08.26 |
| 정렬 알고리즘 (0) | 2022.08.20 |
| 쿼리와 SQL (0) | 2022.08.20 |
문제
https://www.acmicpc.net/problem/10989
10989번: 수 정렬하기 3
첫째 줄에 수의 개수 N(1 ≤ N ≤ 10,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 10,000보다 작거나 같은 자연수이다.
www.acmicpc.net
카운팅 정렬로 숫자 정렬하는 문제. 그러나 이 문제에는 함정카드가 하나 있다. (대충 함정좌 짤)
메모리 제한이 8MB밖에 안된다. 자바랑 코틀린만 많이 준다.
Reference
카운팅 정렬(Counting Sort, 계수 정렬) 알고리즘
읽기 전 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다. 개인적으로 사용해보면서 배운 점을 정리한 글입니다. 카운팅 정렬(Counting Sort, 계수 정렬)이란? .주어진 배열의 값
8iggy.tistory.com
https://seongonion.tistory.com/130
계수(카운팅) 정렬 (Counting sort) with 파이썬(Python)
카운팅 정렬, 혹은 계수 정렬은 O(n + k)의 시간복잡도를 가진 정렬이다. 여기서 다소 낯선 k는 정렬을 수행할 배열의 가장 큰 값을 의미한다. k가 단순히 상수로 취급되어 생략되지 않고 남아있는
seongonion.tistory.com
https://www.acmicpc.net/board/view/26132
글 읽기 - ★☆★☆★ [필독] 수 정렬하기 3 FAQ ★☆★☆★
댓글을 작성하려면 로그인해야 합니다.
www.acmicpc.net
https://scarlett-choi.tistory.com/9
[백준 #10989] 수 정렬하기3(카운팅 정렬) - 파이썬(python)
처음엔 똑같은 문제가 계속 나와서 왜 그런거지 생각하면서 전에 했던 것 대로 똑같이 했더니 계속 메모리 초과가 났다.. 아마 input,count,ouput array를 다 따로 만들어서 그런듯,, 카운팅 정렬을 이
scarlett-choi.tistory.com
풀이
문제를 보면 아시겠지만 이전의 정렬 문제와 달리 숫자가 중복이 된다. 우리야 숫자 같으니까 똑같이 두지 뭐 하지만 컴퓨터는 이게 뭐여 하면서 밥상뒤집기를 시전할 수도 있다. 그래서 이럴 때 필요한 게 카운팅 정렬임… 함정 얘기는 이따가 해드릴게여.
a = [1, 2, 6, 5, 6, 6, 4, 3, 3, 4, 2]
def count_sort(arr):
m = max(arr)
# 최댓값 도출
C = [0] * (m + 1)
# Counting Array 생성
for a in arr:
C[a] += 1
print("Counting Array: {}".format(C))
# counting Array에 채워넣는다
for i in range(1, m + 1):
C[i] += C[i - 1]
print("Array's Sum: {}".format(C))
# 누적합으로 바꾼다
result = [0] * len(arr)
# 정렬을 위한 배열
for a in arr:
result[C[a] - 1] = a
C[a] -= 1
print("Sorting... :{}".format(result))
# 정렬 콜
return result
print(count_sort(a))이게 카운팅 정렬의 코드이다. 뭐야 최댓값이 왜 나와요 저 배열 뭔데요…
카운팅 정렬이 진행되는 과정에서는 배열이 두 개 필요하다. 첫번째가 Counting Array, 두번째는 결과를 만들기 위한 배열이다. Counting Array는 말 그대로 이 배열에 어떤 원소가 몇 개 있느냐를 표시하기 위한 배열로, 배열 전체를 돌면서 원소를 세고 있을때마다 카운트를 하나씩 올리는 방식이다. 이렇게 배열 내 원소를 전부 셌다면, 그 다음은 누적합(개수의 누적합)을 구해 배열화하게 된다. 근데 이것만 하면 정렬이 되나요? 된다.
누적합 배열을 통해 개수를 유추할 수 있으니, 어디에서 어디까지 어떤 원소가 들어가게 되는 지 알 수 있기 때문에 알아서 채우면 된다.
그럼 저거 내면 되나요?

메모리 초과: YOU JUST ACTIVATED MY TRAP CARD (브금은 셀프)
위에서 자바랑 코틀린 말고 메모리가 8메가라고 했는데, 저거 일일이 받아서 배열에 저장하면 초과 뜬다.
import sys
N = int(sys.stdin.readline())
array = [0] * 10001
for i in range(N):
input_num = int(sys.stdin.readline())
array[input_num] = array[input_num] + 1
for i in range(10001):
if array[i] != 0:
for j in range(array[i]):
print(i)그래서 이거 내야됨. 아닛 이 짤막한 코드로 된다고? ㅇㅇ 됨 내가 봤음.
위에서 카운팅 정렬은 입력받은 배열에서 세기 위한 배열과 결과를 저장할 배열 두 개를 만든다고 했는데, 요 작고 소듕한 코드는 그 만드는 과정을 생략해버렸다.
그래서 만드는 배열은 0이 10001개인 배열 하나뿐이고, 숫자가 입력될때마다 배열의 입력받은 값에 해당하는 인덱스의 숫자를 하나 추가한다. 이게 뭔 소리냐면 배열이 다 0이고 입력값이 7이면 배열[7]을 0에서 1로 바꾼다는 얘기. 그리고 배열을 싹 돌아서 안에 0이 아닌 숫자가 있으면 그만큼 해당 숫자를 출력한다.
'BOJ > [BOJ] Python' 카테고리의 다른 글
| 백준 2108번 풀이 (0) | 2022.08.23 |
|---|---|
| 백준 25305번 풀이 (0) | 2022.08.23 |
| 백준 2750번 풀이 (0) | 2022.08.20 |
| 백준 1436번 풀이 (0) | 2022.08.20 |
| 백준 1018번 풀이 (0) | 2022.08.20 |